This section describes how to set up a PostgreSQL gateway 2.0 instance. See the migration guide if you’re migrating from a previous version.
Before you start
Make sure you have registered the Cognite API and the CDF application in Microsoft Entra ID and set up Microsoft Entra ID and CDF groups to control access to CDF data.Step 1: Register an app in Microsoft Entra ID to use with PostgreSQL gateway
1
Sign in to Azure portal
Sign in to the Azure portal as an admin.
2
Select tenant
If you have access to multiple tenants, use the Directory + subscription filter in the top menu to select the tenant in which you want to register an application.
3
Navigate to Microsoft Entra ID
Search for and select Microsoft Entra ID.
4
Register new application
Under Manage, select App registrations > New registrations.In the Register an application window, enter the app name, and then select Register.
5
Copy application ID
Copy and make a note of the Application (client) ID. This value is required to create user credentials for the PostgreSQL gateway.
6
Create client secret
- Under Manage, select Certificates & secrets.
- Select New client secret.
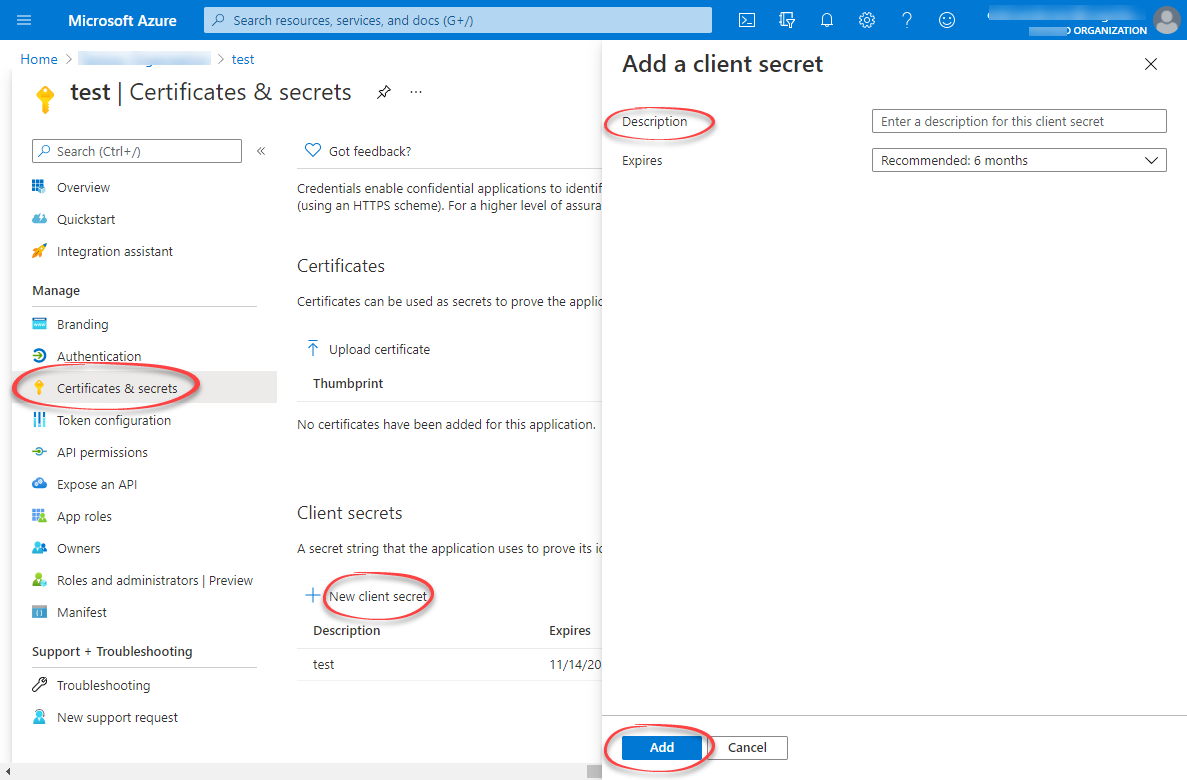
- Enter a client secret description.
- Select an expiry time.
- Select Add.
7
Copy client secret
Copy and make a note of the client secret in the Value field.
Step 2: Create a group in Microsoft Entra ID and add the registered app as its member
1
Open groups
Open the overview window in Microsoft Entra ID and select Manage > Groups.
2
Create group
Create a group, read more here.
3
Add app as member
- Open the group. Under Manage, select Members > Add members.
- Find the app you created above and click Select.
4
Copy Object ID
Return to the overview, and then copy and make a note of the Object Id.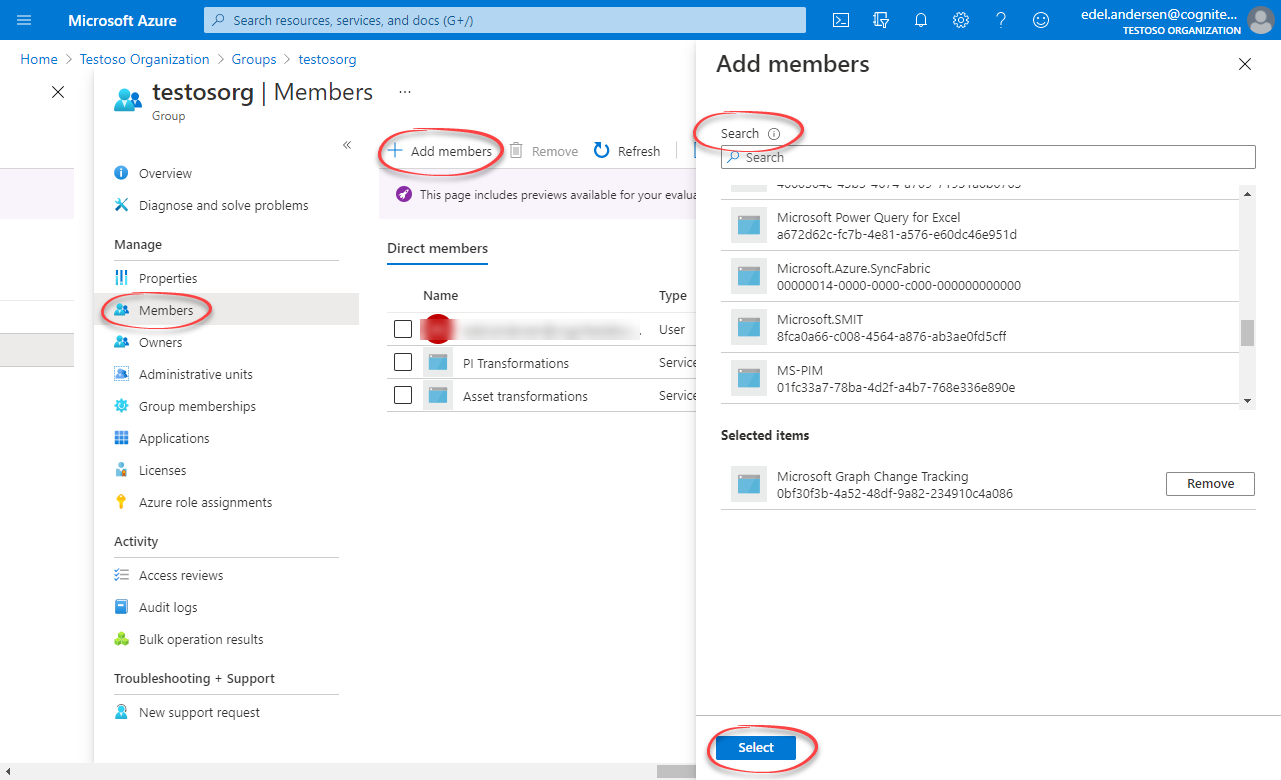
Step 3: Create a group in CDF and link to the Microsoft Entra ID group
1
Navigate to CDF groups
Sign in to CDF as an admin and naviate to Admin > Groups > Create new group.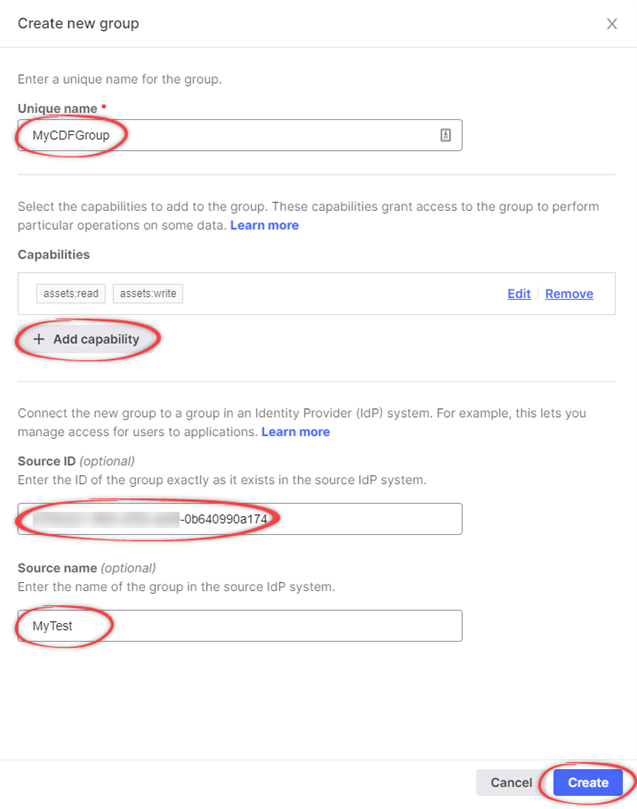
2
Name the group
In the Create a new group window, enter a unique name for the group.
3
Add capabilities
Add relevant capabilities. The minimum required capabilities are:
postgresGateway:READpostgresGateway:WRITEproject:listgroups:listsession:CREATE
read and/or write capabilities for the CDF resources you want to ingest data into. For instance, if you’re ingesting assets, add asset:read and asset:write.If you revoke the capabilities in the CDF group, you also revoke access for the PostgreSQL gateway.
4
Link to Microsoft Entra ID group
Link the CDF group to a Microsoft Entra ID (ME-ID) group:
- In the Source ID field, enter the Object Id for the ME-ID group exactly as it exists in ME-ID.
- In the Source name field, enter the name of the group in Microsoft Entra ID.
5
Create group
Select Create.
Step 4: Create user credentials for the PostgreSQL gateway
1
Send POST request
Send a POST request to
https://{cluster}.cognitedata.com/api/v1/projects/{project}/postgresgateway API.Where:
clusteris where your CDF instance exists. If you don’t know the cluster name, contact Cognite support.projectis the organization name of your CDF instance.
2
Get Bearer token
Get a Bearer token from your identity provider for authentication. To get a bearer token from Postman, see the illustration below.
3
Get session nonce
Get the sessions nonce using the Cognite API using the Bearer token obtained from above.
4
Provide nonce to API
Provide the nonce to the API endpoint:The service returns, among other things, a username and password with the same CDF capabilities as the group you created in CDF. Make sure to keep these, as they are required when you set up the gateway connection in your ETL tool.
Migrate to PostgreSQL gateway 2.0
The PostgreSQL gateway 2.0 replaces the previous version (1.0). As indicated in Step 4 above, this version usessessions on behalf of your project and OIDC authentication to make requests to CDF.
Most of the tables remain the same, but may have columns added or renamed. Some tables have been changed or divided up for clarity.
These modifications are highlighted below:
Assets
Table name: assets AddedEvent
Table name: events AddedExtraction pipeline runs
Table name: extraction_pipeline_runs AddedExtraction pipelines
Table name: extraction_pipelines AddedFiles
Table name: files AddedLabels
Table name: labels AddedSequences
Table name: sequences AddedSequence rows
Table name: sequence_rows ChangedDatapoints
Thedatapoints table has been divided into 2 different tables because version 1.0 only supported double datapoints. These are string_datapoints and double_datapoints.
It includes the following columns:
Timeseries
Thetimeseries table has been renamed to time_series.
Removed
The legacy_name field has been retired and is no longer available for use.
Raw
Theraw table is renamed to raw_rows for better understanding and proper differentiation between raw table data sets and raw table names.
raw_rows
Added
Changed
raw_tables
Added