Before you start
- Make sure you have an Azure subscription and have created Azure resource groups.
- Make sure you have created an Azure storage account.
- Make sure you have the file containing the data to be ingested to CDF in Azure blob storage.
Step 1: Create a data factory
1
Sign in to Azure
- Sign in to the Azure portal as an admin.
- If you have access to multiple tenants, use the Directory + subscription filter in the top menu to select the tenant in which you want to register a data factory.
2
Navigate to Data Factory
Search for and select Data Factory.Select Create to open the Data Factory page.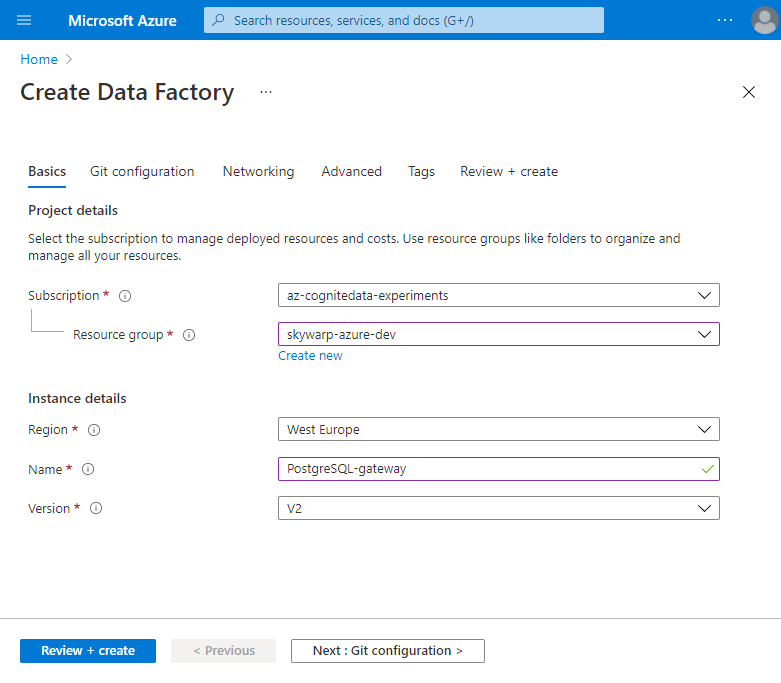
3
Configure basics
On the Basics tab:
- Subscription: Select the Azure subscription in which you want to create the data factory.
- Resource group: Create or select the Azure resource group you want to use.
- Region: Select a location where your ADF metadata will be stored. This list only shows locations that ADF supports.
- Name: Enter a globally unique name for the data factory.
- Version: Select V2.
4
Configure Git
Select Next: Git configuration and fill in the required fields or select Configure Git later.
5
Create data factory
Select Review + Create > Create.
6
Open Azure Data Factory application
After the creation is complete, open the data factory and select the Author & Monitor tile to start the Azure Data Factory application in a separate tab.
Step 2: Create an ADF pipeline and set the source system
Use the Copy data tool to create a pipeline that reads data from a file in your data storage and writes to CDF.1
Create pipeline
On the Let’s get started page, select the Create pipeline tile.
2
Open Copy data activity
Open Activities > Move and transform.Drag and drop the Copy data onto the canvas and enter a unique name in the Name field.
3
Configure source
Open the Source tab > New.Select the datastore that references the source system you’re extracting from. In this example, we’ll extract data from a .csv file in Azure Blob Storage.Select Continue.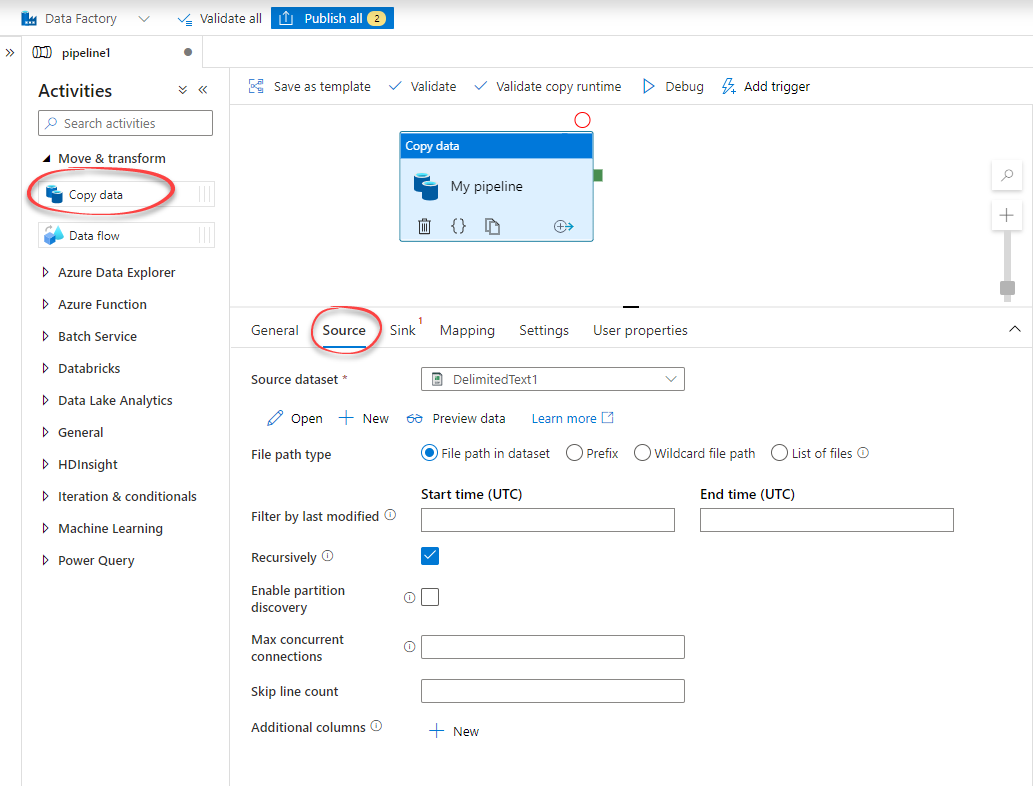
4
Create linked service
Create a new linked service that links your data store to the data factory.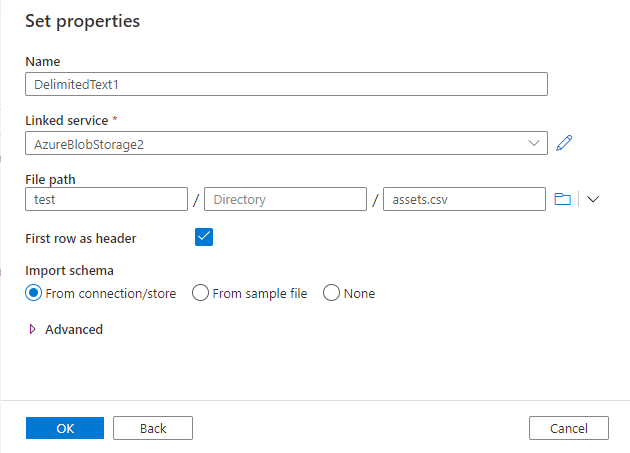
- Enter a unique name for the service.
- Select your Azure subscription and storage account.
- Select Test connection to make sure you are connected to the selected storage account.
- Select Create.
5
Set properties
Under Set properties, set the file you want to read data from.
- Enter a unique name for the source data set.
- Browse to the file you want to use.
- Select First row as header to reuse the source file’s header columns.
- Select OK.
Step 3: Set PostgreSQL gateway as sink
In this step, add the PostgreSQL gateway as the destination using a sink in ADF.1
Open Sink tab
Open Copy data > Sink tab.
2
Create new sink dataset
In the Sink dataset field, select New.Select or search for Azure Database for PostgreSQL.Select Continue.
3
Open sink dataset
Select Open to open the sink data set.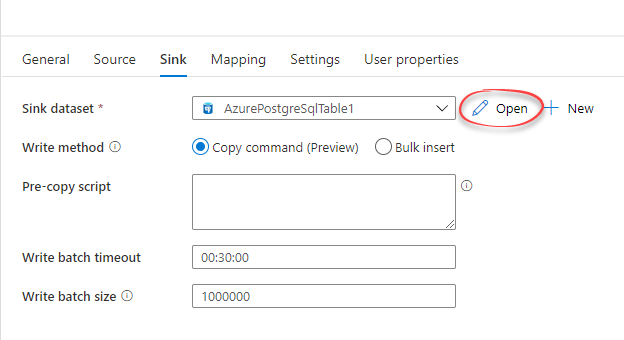
4
Configure linked service
On the Connection tab, add a linked service for the sink data set.
- Select New to add a linked service.
- Under Account selection method > Enter manually.
- In the Fully qualified domain name field, enter
fdw.{cluster}.cogniteapp.comwhere{cluster}is where your CDF instance is installed. If you don’t know the cluster name, contact Cognite support. - In the Port field, enter 5432, which is the default port for the PostgreSQL gateway.
- For Database name and User name, enter the username returned from the PostgreSQL gateway.
- In the Password field, enter the password returned from the PostgreSQL gateway.
- In the Encryption method field, select SSL. This ensures that the communication between ADF and CDF are encrypted.
- Optionally, select Validate server certificate.
- Select Test connection to make sure you are connected to the Azure database for PostgreSQL.
5
Create linked service
Select Create.
Step 4: Set the destination database table
Back on the Connection tab, you need to select the destination table from the tables available in your PostgreSQL gateway database. You can choose between several resource types like assets, events, and data points.1
Select destination table
In the Table field, select the table matching the destination CDF RAW table or the CDF resource type 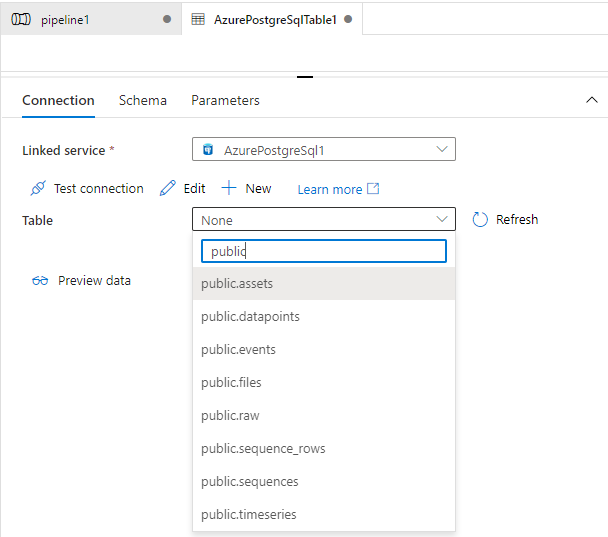
public.<cdf_resource_type>, for instance, public.assets or public.time_series.Step 5: Map the source and destination tables
1
Open Mapping tab
Open the Mapping tab on your pipeline.
2
Import schemas
Select Import schemas to import the table columns and remove the lines you won’t use.
3
Map columns
Map the columns according to your requirements.
4
Run debug
Select Debug in the top bar to run the PostgreSQL gateway.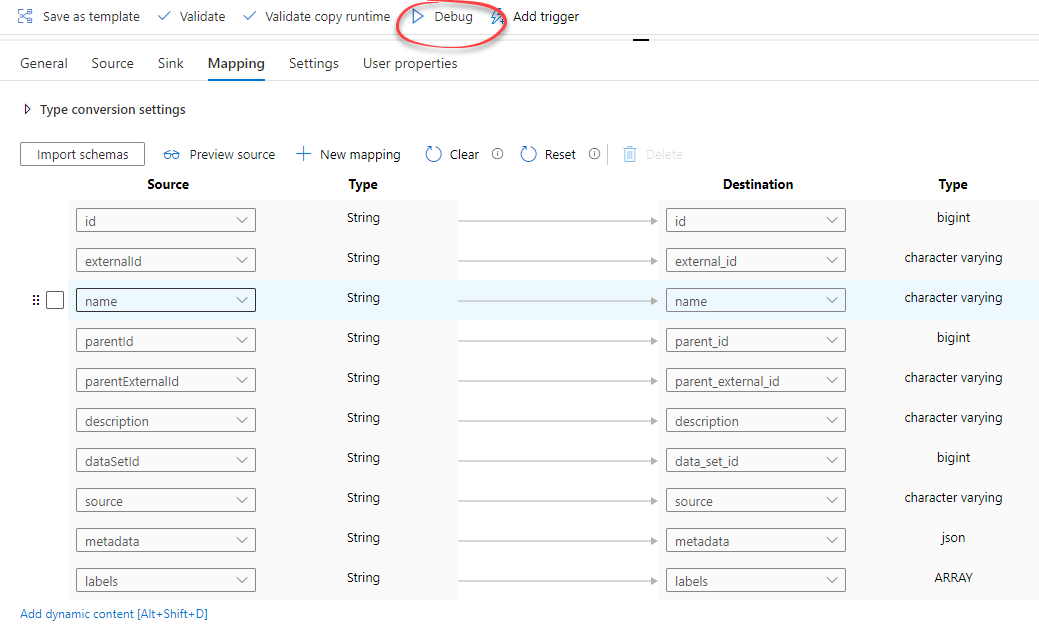
Step 6: Report run status for data extractions
Monitor the data integration into CDF to quickly catch failed runs to start troubleshooting and notify data set owners and stakeholders. You can see an overview of all extraction pipelines’ status on the Extraction pipelines page. To set up status reporting:1
Open Azure Data Factory
Open Azure Data Factory.
2
Add success activity
Navigate to the Copy data activity created for the extraction pipeline, select the plus (+) sign, and select Success.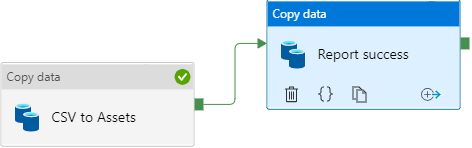
3
Configure success Copy data activity
Drag and drop an additional Copy data activity onto the canvas and link it to the Success activity.
4
Configure success Source tab
On the Source tab:
- Enter a source data set, but note that no data is read from this data set. You can, for instance, enter the data set already used in the previous pipeline.
- Create two additional columns named
integration_statuswith contentsuccessandintegration_external_idwith the extraction pipeline’s external ID as content.
5
Configure success Sink tab
On the Sink tab: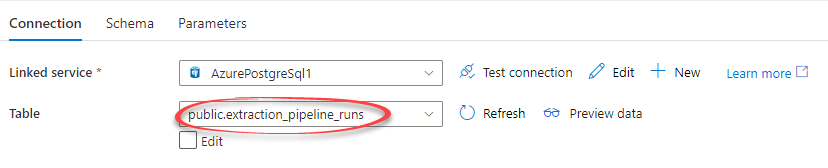
- In the Sink dataset field, select New and reuse the sink and linked service from the previous pipeline.
- In the Table field, browse and select the foreign table
public.extraction_pipeline_runs.
For a large dataset, set the
Write method to Copy command.6
Configure success Mapping tab
On the Mapping tab, create two mapping rows:
- Row 1: Enter
integration_external_IDas source and theexternalIdas destination. - Row 2: Enter
integration_statusas source andstatusas destination.
7
Add failure activity
Navigate back to the Copy data activity created for the pipeline, select the plus (+) sign, and select Failure.
8
Configure failure Copy data activity
Drag and drop an additional Copy data activity onto the canvas and link to the Failure activity.Follow the steps above, but on the Source tab, enter 
failure as content for the integration_statuscolumn.Troubleshooting
Invalid token If you have a valid token but still getinvalid token when you create a user in the PostgreSQL gateway, try these solutions:
- The groups in Microsoft Entra ID and CDF are correctly linked in Manage & Configure > Access management in CDF. See step 3 above.
-
The CDF group is set up with the
Project:listandGroup:listcapabilities in Manage & Configure > Access management in CDF.