Before you start
To stage data in CDF RAW, you need the capabilities listed here. Contact your CDF project admin if you don’t have the necessary capabilities.Set up databases and tables in CDF RAW
Use the RAW explorer to set up databases and tables before ingesting data in its original form. Keeping the original form of the data reduces the load on the source systems, allows you to minimize logic in the extractors, and makes it easy to re-run transformations on data in the cloud. The example below shows how you can upload files in CSV or JSON format to CDF RAW.Create a database
Select Create database, enter a unique name, and select Create. Note that you can’t rename a database.
Create a table
Select Create table, enter a unique name, and select Create. Note that you can’t rename a table.
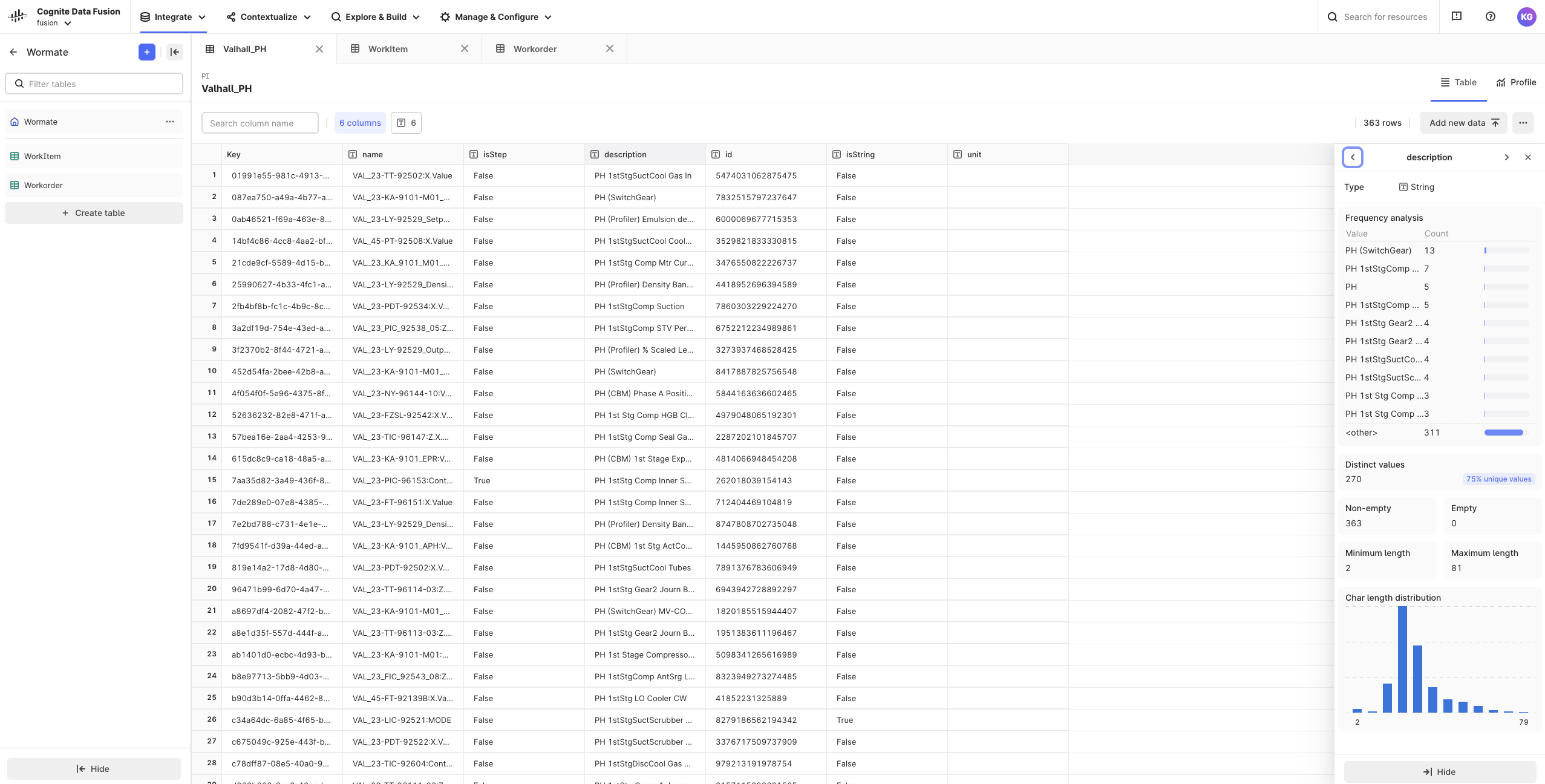
Data profiling and data viewing
Discover patterns and outliers, and see other statistics on the Profile tab to get in-depth knowledge about the data quality. You can also view the actual data and sort and filter each column on the Table tab. Report your findings to the data owners to find the best fit for the primary key column and contextualization and to provide the best support for the end-users of the data. Keep iterating on the data integrations to improve the data quality and prepare the data transformation into the CDF data model. See Transform data to get started. Profiling has a maximum limit of 1 million rows per table. Rows exceeding the limit won’t be profiled.