Integrate data
To analyze and contextualize your data in Cognite Data Fusion (CDF), you need to establish efficient data integration pipelines between your existing data infrastructure and the CDF data model.
In CDF, a data integration pipeline typically includes steps to extract, transform, and contextualize data. In this unit, we'll have a closer look at each of these steps.
To integrate data into the CDF data model, you can use standard protocols and interfaces like PostgreSQL and OPC-UA as well as Cognite or 3rd party extractor and transformation tools. The tools are essential to your data operations, and we recommend that you use a modular design for your data integration pipelines to make them as maintainable as possible.
Extract data
The extract tools connect to the source systems and push data in its original format to the staging area. Data extractors operate in different modes. They can stream data or extract data in batches to the staging area. Also, they can extract data directly to the CDF data model with little or no data transformation.
With read access to the data sources, you can set up the system integration to stream data into the CDF staging area (RAW), where the data can be normalized and enriched. We support standard protocols and interfaces like PostgreSQL and OPC-UA to facilitate data integration with your existing ETL tools and data warehouse solutions.
We also have extractors that are custom-built for industry-specific systems and standard off-the-shelf ETL tools for more traditional tabular data in SQL-compatible databases.
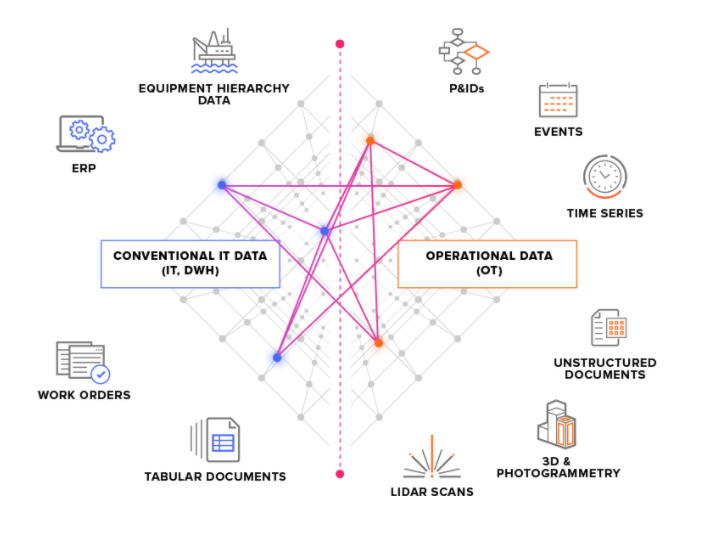
We divide source systems into two main types:
-
OT source systems - for example, industrial control systems with time series data. Getting OT data into CDF can be time-critical (a few seconds), and the data often need to be extracted continuously.
-
IT source systems - for example, ERP systems, file servers, databases, and engineering systems (3D CAD models). IT data typically change less frequently (minutes or hours) than OT data and can often be extracted in batch jobs.
Staging area alternatives
Data flows from the extractors into the CDF ingestion API. From here on, everything lives in the cloud. The first stop is the CDF staging area (RAW), where tabular data is stored in its original format. This approach lets you minimize logic in the extractors and to run and re-run transformations on data in the cloud.
If you already have your data streamed to and stored in the cloud, for instance, in a data warehouse, you can integrate the data into the CDF staging area from there and transform the data with Cognite's tools. Alternatively, you can transform the data in your cloud and bypass the CDF staging area to integrate the data directly into the CDF data model.
Transform data
The transform step shapes and moves the data from the staging area into the CDF data model. This is the step that typically hosts most of the data processing logic.
Data transformation typically includes one or more of these steps:
- Re-shape the data to fit the
CDFdata model. For example, read a data object fromCDF RAWand shape it into an event. - Enrich the data with more information. For example, add data from other sources.
- Match the data with other data objects in your collection.
- Analyze the quality of the data. For example, check if all the required information is present in the data object.
We recommend using your existing Extract, Transform, Load (ETL) tools to transform the data, but we also offer the CDF Transformation tool as an alternative for lightweight transformation jobs. With CDF Transformations, you can use Spark SQL queries to transform data from within your browser.
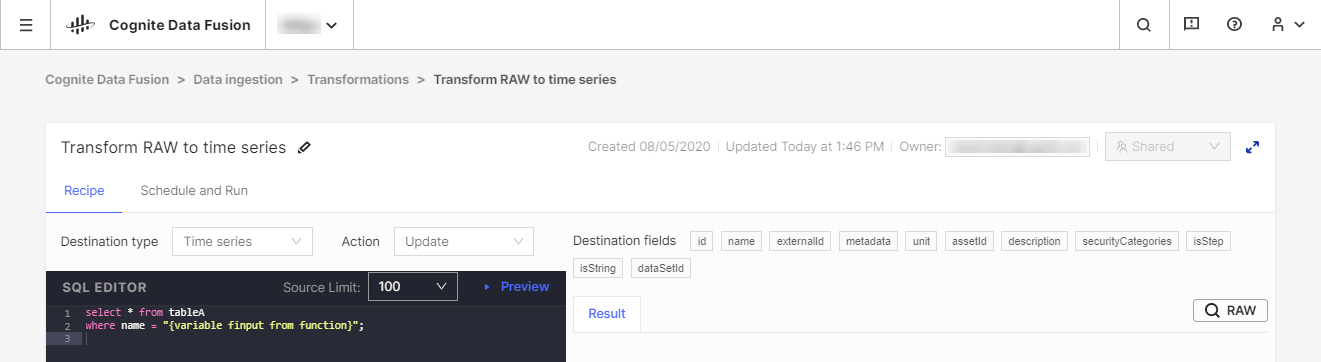
Regardless of the tool you use, you will be transforming data from CDF's RAW storage or an equivalent staging system into the Cognite data model, where you can further enrich the data with more relationships for in-depth analytics and real-time insight.
Enhance data
An all-important piece of your data integration pipelines is contextualization. This process combines machine learning, a powerful rules engine, and domain knowledge to map resources from different source systems to each other in the CDF data model.
The first part of contextualization is to ensure that each unique entity shares the same identifier in CDF, even if it has different IDs in the source systems. This step is mostly performed during the transformation stage when you shape and match incoming data and compare it with existing resources in your collection.
The next step in the contextualization process is to associate entities with each other in the same way they relate in the real world. For instance, an object inside a 3D model may have an ID you can map to an asset, and a time series from an instrument monitoring system can have another ID you can assign to the same asset.
The interactive contextualization tools in CDF let you combine machine learning, a powerful rules engine, and domain expertise to map resources from different source systems to each other in the CDF data model.
For example, you can build interactive engineering diagrams from static PDF source files, and match entities to set up, automate and validate all your contextualization pipelines from your browser without having to write any code.
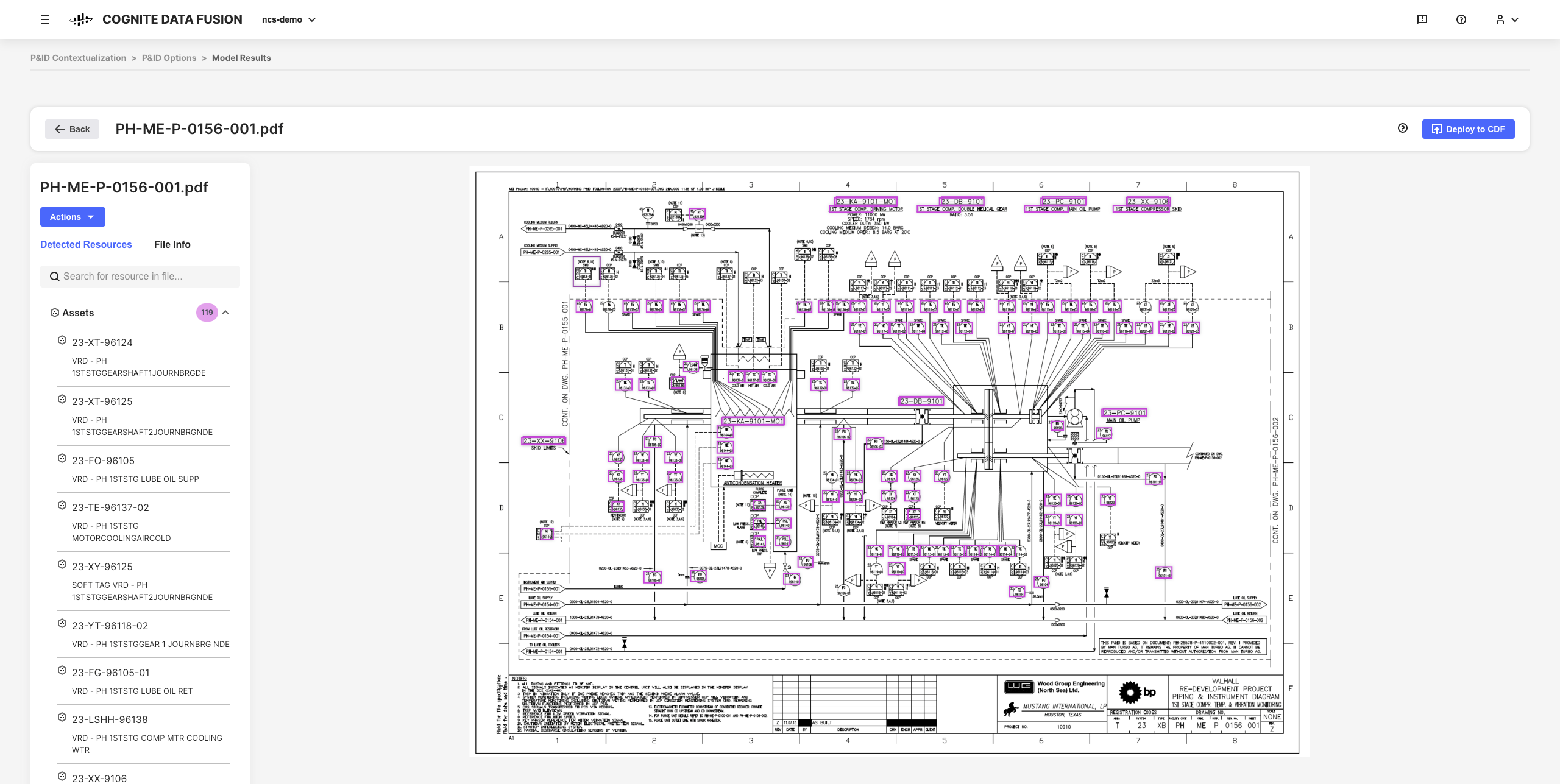
The resulting refined data and inferred insights are the foundation for scaling your CDF implementation and solutions across your organization as you develop a deeper understanding of your data.