Integrera data
För att analysera och kontextualisera dina data i Cognite Data Fusion (CDF), måste du upprätta effektiva dataintegrationspipelines mellan din befintliga datainfrastruktur och CDF-datamodellen.
I CDF innehåller en dataintegrationspipeline vanligtvis steg för att extrahera, transformera och kontextualisera data. I den här enheten kommer vi att titta närmare på vart och ett av dessa steg.
För att integrera data i CDF-datamodellen kan du använda standardprotokoll och gränssnitt som PostgreSQL och OPC-UA samt Cognite eller tredjepartsextraktions- och transformationsverktyg. Verktygen är viktiga för din dataverksamhet och vi rekommenderar att du använder en modulär design för dina dataintegrationspipelines för att göra dem så underhållbara som möjligt.
Extrahera data
Verktygen för extrahering ansluter till källsystemen och skickar data i sitt ursprungliga format till iscensättningsområdet. Dataextraktorer fungerar i olika lägen. De kan streama data eller extrahera data i batcher till uppställningsområdet. De kan också extrahera data direkt till CDF-datamodellen med liten eller ingen datatransformation.
Med läsbehörighet till datakällorna kan du ställa in systemintegrationen för att strömma data till CDF-platsen (RAW) där data kan normaliseras och berika. Vi stöder standardprotokoll och gränssnitt som PostgreSQL och OPC-UA för att underlätta dataintegration med dina befintliga ETL-verktyg och datalagerlösningar.
Vi har även extraktorer som är specialbyggda för branschspecifika system och standardiserade ETL-verktyg för mer traditionella tabelldata i SQL-kompatibla databaser.
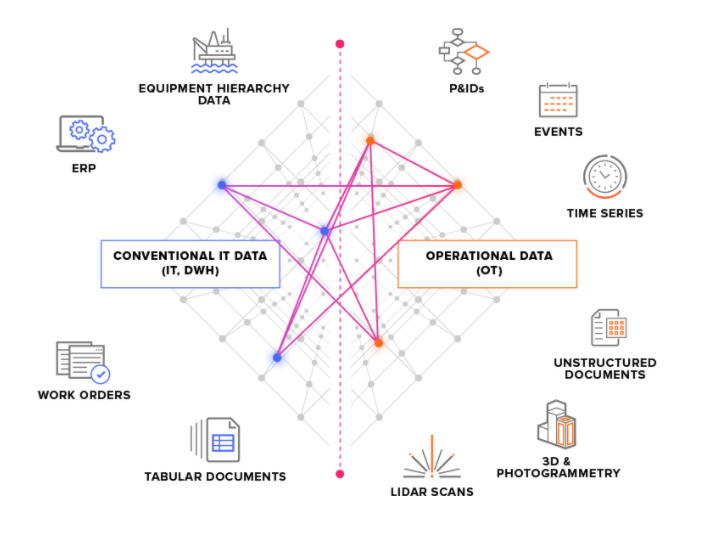
Vi delar in källsystem i två huvudtyper:
-
OT-källsystem – till exempel industriella styrsystem med tidsseriedata. Att få in OT-data till CDF kan vara tidskritisk (några sekunder), och data behöver ofta extraheras kontinuerligt.
-
IT-källsystem – till exempel ERP-system, filservrar, databaser och tekniska system (3D CAD-modeller). IT-data ändras vanligtvis mindre ofta (minuter eller timmar) än OT-data och kan ofta extraheras i batch-jobb.
Platsalternativ
Data flödar från extraktorerna till CDF-intags-API. Från och med nu lever allt i molnet. Det första stoppet är CDF-platsen (RAW), där tabelldata lagras i sitt ursprungliga format. Detta tillvägagångssätt låter dig minimera logiken i extraktorerna och att köra och köra om transformationer på data i molnet.
Om du redan har dina data streamade till och lagrade i molnet, till exempel i ett datalager, kan du integrera data i CDF-lagringsområdet därifrån och omvandla dem med Cognite's verktyg. Alternativt kan du omvandla data i ditt moln och kringgå CDF-platsen för att integrera data direkt i CDF-datamodellen.
Transformera data
Steget transformera formar och flyttar data från mellanställningsområdet till CDF-datamodellen. Detta är steget som vanligtvis är värd för det mesta av databehandlingslogiken.
Datatransformation inkluderar vanligtvis ett eller flera av dessa steg:
- Omforma data för att passa datamodellen
CDF. Läs till exempel ett dataobjekt frånCDF RAWoch forma det till en händelse. - Berika data med mer information. Lägg till exempel till data från andra källor.
- Matcha data med andra dataobjekt i din samling.
- Analysera datakvaliteten. Kontrollera till exempel om all nödvändig information finns i dataobjektet.
Vi rekommenderar att du använder dina befintliga Extract, Transform, Load (ETL)-verktyg för att transformera data, men vi erbjuder också verktyget CDF Transformation som ett alternativ för lättviktstransformationsjobb. Med CDF Transformations kan du använda Spark SQL-frågor för att transformera data från din webbläsare.
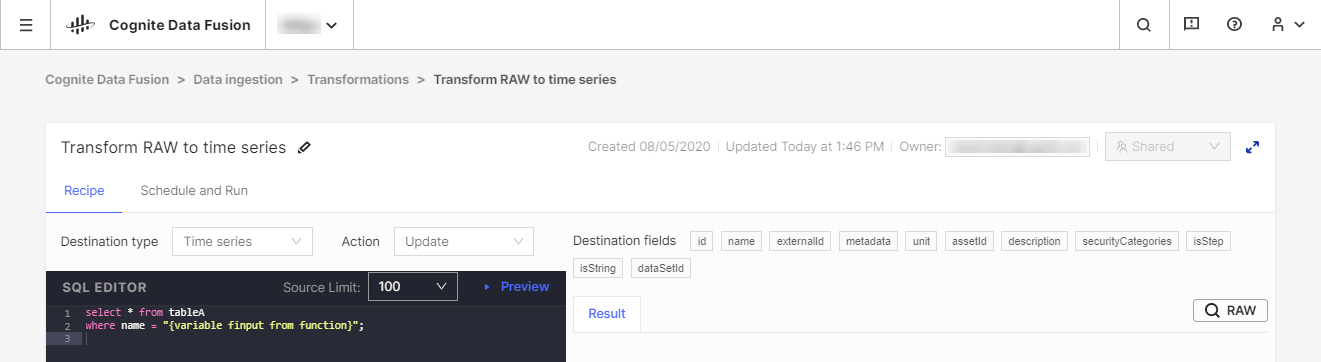
Oavsett vilket verktyg du använder kommer du att omvandla data från CDF's RAW-lagring eller ett likvärdigt mellanlagringssystem till Cognite-datamodellen, där du kan berika data ytterligare med fler relationer för djupgående analyser och realtid insikt.
Förbättra data
En mycket viktig del av dina dataintegrationspipelines är kontextualisering. Denna process kombinerar maskininlärning, en kraftfull regelmotor och domänkunskap för att kartlägga resurser från olika källsystem till varandra i datamodellen CDF.
Den första delen av kontextualisering är att säkerställa att varje unik enhet delar samma identifierare i CDF, även om den har olika ID i källsystemen. Detta steg utförs mestadels under transformationsstadiet när du formar och matchar inkommande data och jämför dem med befintliga resurser i din samling.
Nästa steg i kontextualiseringsprocessen är att associera enheter med varandra på samma sätt som de förhåller sig i den verkliga världen. Till exempel kan ett objekt inuti en 3D-modell ha ett ID som du kan mappa till en tillgång, och en tidsserie från ett instrumentövervakningssystem kan ha ett annat ID som du kan tilldela samma tillgång.
De interaktiva kontextualiseringsverktygen i CDF låter dig kombinera maskininlärning, en kraftfull regelmotor och domänexpertis för att kartlägga resurser från olika källsystem till varandra i CDF-datamodellen.
Du kan till exempel bygga interaktiva tekniska diagram från statiska PDF-källfiler och matcha enheter för att ställa in, automatisera och validera alla dina kontextualiseringspipelines från din webbläsare utan att behöva skriva någon kod.
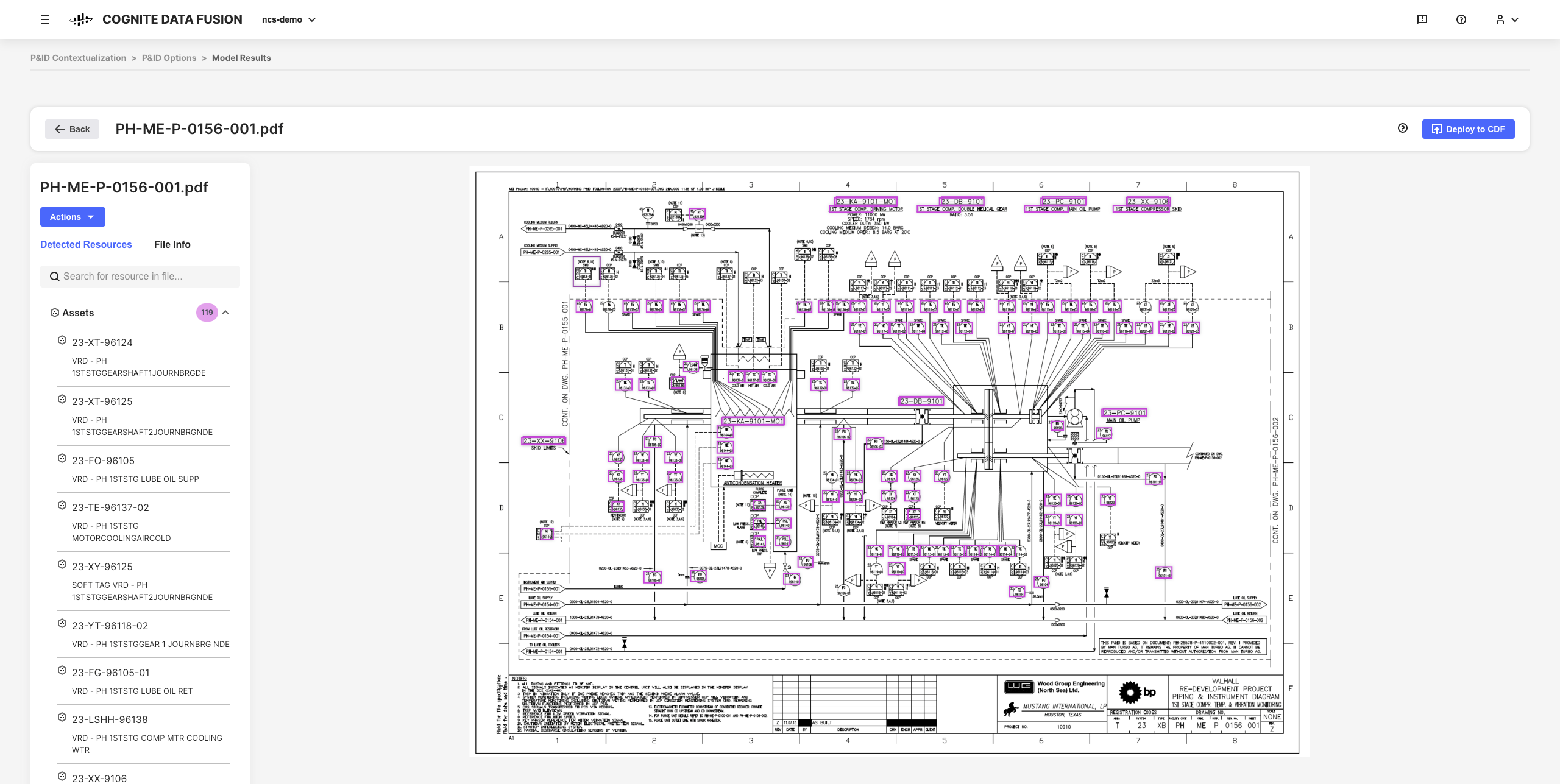
Den resulterande förfinade data och härledda insikter är grunden för att skala din CDF-implementering och lösningar i hela din organisation när du utvecklar en djupare förståelse av din data.