Gegevens integreren
Als u uw gegevens in Cognite Data Fusion (CDF) wilt analyseren en contextualiseren, moet u efficiënte pijplijnen voor gegevensintegratie tot stand brengen tussen uw bestaande gegevensinfrastructuur en het CDF-gegevensmodel.
Een pijplijn voor gegevensintegratie in CDF bevat doorgaans stappen om gegevens te extraheren, te transformeren en te contextualiseren. In dit gedeelte gaan we dieper in op elk van deze stappen.
Als u gegevens wilt integreren in het CDF-gegevensmodel, kunt u standaardprotocollen en -interfaces gebruiken, zoals PostgreSQL en OPC-UA, of gebruikmaken van de extractie- en transformatietools van Cognite of van derden. De tools zijn essentieel voor uw gegevensbewerkingen en we raden u aan een modulair ontwerp te gebruiken voor uw pijplijnen voor gegevensintegratie, zodat u ze zo goed mogelijk kunt onderhouden.
Gegevens extraheren
De extractietools maken verbinding met de bronsystemen en pushen gegevens in de oorspronkelijke indeling naar het faseringsgebied. Gegevensextractors werken in verschillende modi. Ze kunnen gegevens streamen of gegevens in batches extraheren naar het faseringsgebied. Ze kunnen gegevens ook rechtstreeks extraheren naar het CDF-gegevensmodel, met weinig of geen gegevenstransformatie.
Met leestoegang tot de gegevensbronnen kunt u instellen dat de systeemintegratie gegevens naar het CDF-faseringsgebied (RAW) streamt, waar de gegevens kunnen worden genormaliseerd en verrijkt. We ondersteunen standaardprotocollen en -interfaces zoals PostgreSQL en OPC-UA om gegevensintegratie met uw bestaande ETL-tools en datawarehouses te vergemakkelijken.
We hebben ook extractors die op maat zijn gemaakt voor branchespecifieke systemen en standaard kant-en-klare ETL-tools voor meer traditionele tabelgegevens in SQL-compatibele databases.
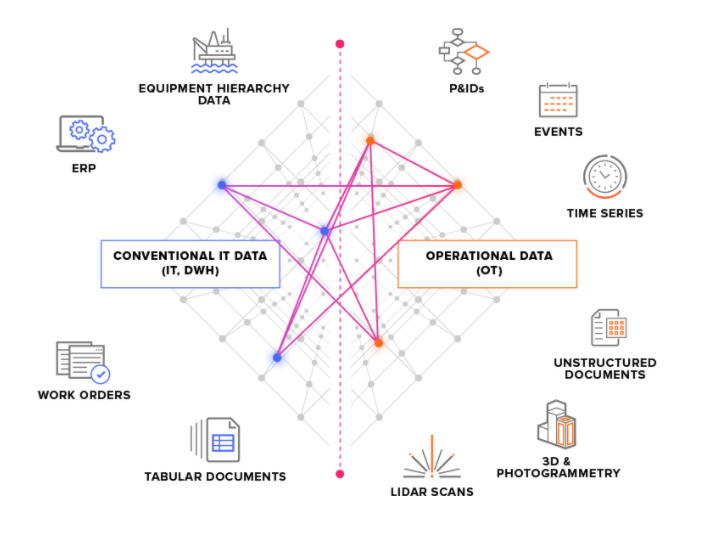
We onderscheiden twee hoofdtypen bronsystemen:
-
OT-bronsystemen: bijvoorbeeld industriële besturingssystemen met tijdreeksgegevens. Het ophalen van OT-gegevens voor CDF kan tijdkritisch zijn (enkele seconden) en de gegevens moeten vaak continu worden geëxtraheerd.
-
IT-bronsystemen: bijvoorbeeld ERP-systemen, bestandsservers, databases en technische systemen (3D CAD-modellen). IT-gegevens veranderen doorgaans minder vaak (minuten of uren) dan OT-gegevens en kunnen vaak in batchtaken worden geëxtraheerd.
Alternatieven voor faseringsgebieden
Gegevens stromen van de extractors naar de CDF-invoer-API. Vanaf hieraf gebeurt alles in de cloud. De eerste stop is het CDF-faseringsgebied (RAW), waar tabelgegevens worden opgeslagen in de oorspronkelijke indeling. Met deze aanpak kunt u de logica in de extractors minimaliseren en transformaties (blijven) uitvoeren voor de gegevens in de cloud.
Als u uw gegevens al hebt gestreamd naar en opgeslagen in de cloud, bijvoorbeeld in een gegevenswarehouse, kunt u de gegevens van daaruit integreren in het CDF-faseringsgebied en de gegevens transformeren met de tools van Cognite's. U kunt de gegevens ook transformeren in uw cloud en het CDF-faseringsgebied overslaan om de gegevens rechtstreeks te integreren in het CDF-gegevensmodel.
Gegevens transformeren
In de transformatiestap worden de gegevens gevormd en verplaatst van het faseringsgebied naar het CDF-gegevensmodel. Dit is de stap waar doorgaans de meeste logica voor gegevensverwerking wordt gehost.
Gegevenstransformatie omvat meestal een of meer van de volgende stappen:
- De vorm van de gegevens aanpassen aan het
CDF-gegevensmodel. Lees bijvoorbeeld een gegevensobject uitCDF RAWen transformeer dit tot een gebeurtenis. - De gegevens verrijken met meer informatie. Voeg bijvoorbeeld gegevens uit andere bronnen toe.
- De gegevens koppelen aan andere gegevensobjecten in uw verzameling.
- De kwaliteit van de gegevens analyseren. Controleer bijvoorbeeld of alle vereiste informatie aanwezig is in het gegevensobject.
We raden aan om de gegevens te transformeren met uw bestaande ETL-tools (Extract, Transform, Load), maar we bieden ook de CDF Transformation-tool aan als alternatief voor minder omvangrijke transformatietaken. Met CDF Transformations kunt u Spark SQL-query's gebruiken om gegevens te transformeren vanuit uw browser.
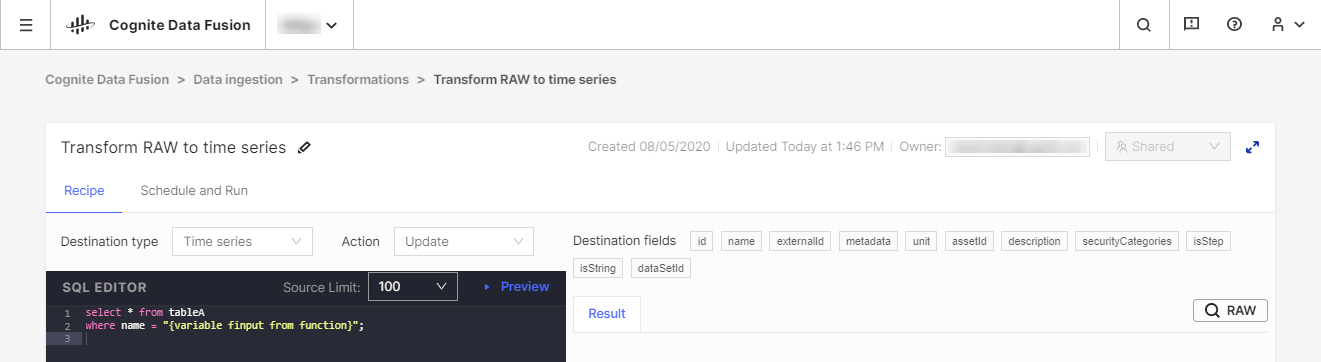
Ongeacht de tool die u gebruikt: u transformeert gegevens van de CDF's RAW-opslag, of een equivalent faseringssysteem, naar het Cognite-gegevensmodel, waar u de gegevens verder kunt verrijken met meer relaties voor diepgaande analyse en realtime-inzicht.
Gegevens verbeteren
Een uiterst belangrijk onderdeel van uw pijplijnen voor gegevensintegratie is contextualisatie. Dit proces combineert machine learning, een krachtige engine voor regels en domeinkennis om resources van verschillende bronsystemen aan elkaar te koppelen in het CDF-gegevensmodel.
Bij de eerste stap van contextualisatie wordt ervoor gezorgd dat elke unieke entiteit dezelfde id deelt in CDF, zelfs als hiervoor verschillende id's bestaan in de bronsystemen. Deze stap wordt meestal uitgevoerd tijdens de transformatiefase wanneer u binnenkomende gegevens vormgeeft en koppelt en vergelijkt met bestaande bronnen in uw verzameling.
De volgende stap in het contextualisatieproces is om entiteiten aan elkaar te koppelen op dezelfde manier als in de fysieke wereld. Een object in een 3D-model kan bijvoorbeeld een id hebben die u kunt koppelen aan een asset, en een tijdreeks van een controlesysteem voor een instrument kan een andere id hebben die u aan dezelfde asset kunt koppelen.
Met de interactieve tools voor contextualisatie in CDF kunt u machine learning, een krachtige engine voor regels en domeinexpertise combineren om resources van verschillende bronsystemen aan elkaar te koppelen in het CDF-gegevensmodel.
U kunt bijvoorbeeld interactieve technische diagrammen bouwen op basis van statische PDF-bronbestanden en entiteiten koppelen om al uw pijplijnen voor contextualisatie te configureren, te automatiseren en te valideren vanuit de browser, zonder code te hoeven schrijven.
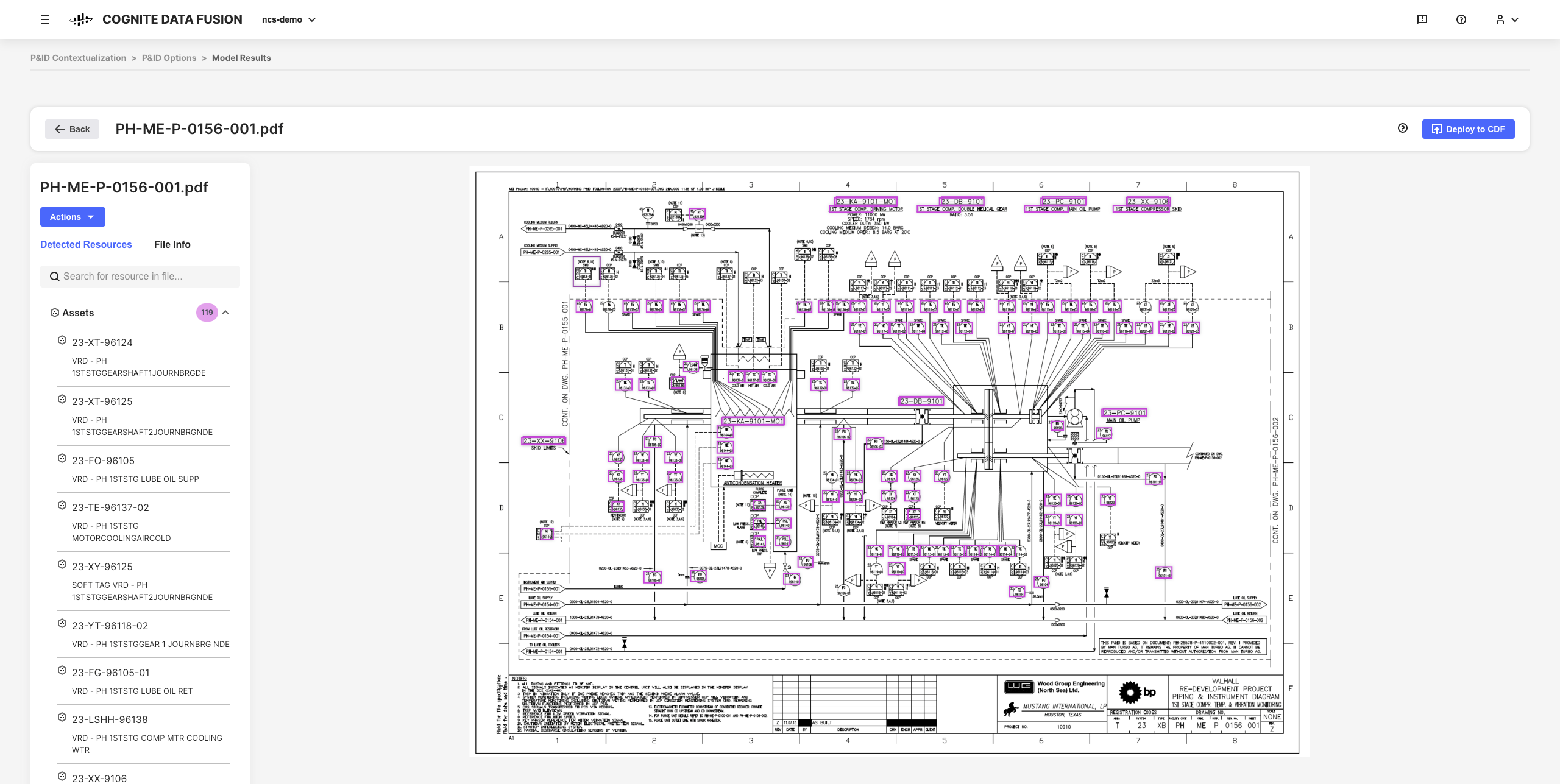
De resulterende verfijnde gegevens en afgeleide inzichten vormen de basis voor het opschalen van uw CDF-implementatie en -oplossingen in uw hele organisatie naarmate u dieper inzicht in uw gegevens ontwikkelt.