Intégration de données
Pour analyser et contextualiser vos données dans Cognite Data Fusion (CDF), vous devez mettre en place des pipelines d’intégration des données efficaces entre votre infrastructure de données existante et le modèle de données de CDF.
Dans CDF, un pipeline d’intégration des données inclut généralement plusieurs étapes pour extraire, transformer et contextualiser les données. Dans cette unité, nous allons étudier chacune de ces étapes en détails.
Pour intégrer les données au modèle de données de CDF, vous pouvez utiliser des protocoles et interfaces standard, tels que PostgreSQL et OPC-UA, ainsi que Cognite ou des outils d’extraction et de transformation tiers. Les outils sont essentiels pour vos opérations sur les données, et nous vous recommandons d’utiliser une conception modulaire pour vos pipelines d’intégration des données, afin de les rendre aussi gérables que possible.
Extraction de données
Les outils d’extraction se connectent aux systèmes source, et poussent des données sous leur format d’origine vers la zone de transit. Les outils d’extractions de données fonctionnent selon différents modes. Ils peuvent diffuser des données en continu, ou extraire des données par lots vers la zone de transit. Ils peuvent aussi extraire des données directement vers le modèle de données de CDF avec peu ou pas de transformation des données.
Avec un accès en lecture aux sources de données, vous pouvez configurer l’intégration du système pour diffuser des données en continu vers la zone de transit CDF (RAW), où les données peuvent être normalisées et enrichies. Nous prenons en charge des protocoles et interfaces standard, tels que PostgreSQL et OPC-UA, pour faciliter l’intégration des données à vos outils d’ETL et solutions d’entreposage de données existants.
Nous avons également des outils d’extraction conçus sur mesure pour des systèmes spécifiques à certains secteurs et des outils d’ETL standard pour les données tabulaires plus traditionnelles dans les bases de données compatibles SQL.
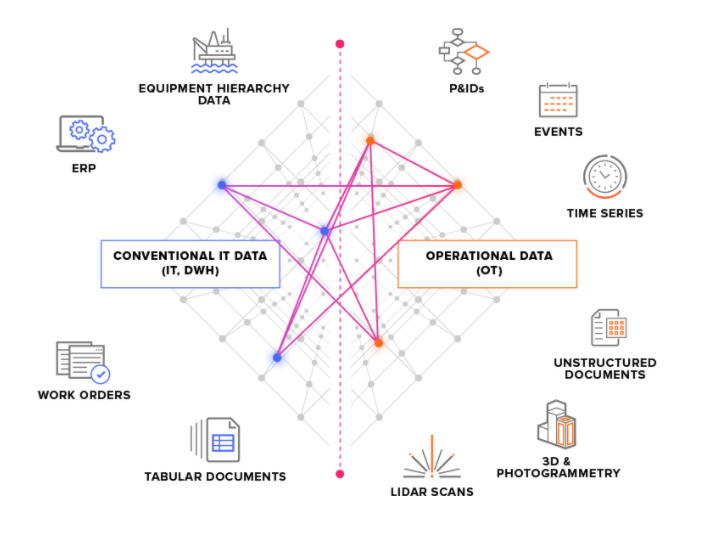
Nous divisons les systèmes source en deux types principaux :
-
Systèmes source OT : par exemple, des systèmes de commande industriels avec des données de séries temporelles. L’obtention de données d’OT dans CDF peut être urgente (quelques secondes), et les données doivent souvent être extraites en continu.
-
Systèmes source IT : par exemple des systèmes d’ERP, des systèmes de fichiers, des bases de données et des systèmes d’ingénierie (modèles de CAO 3D). Les données d’IT changent généralement moins fréquemment (quelques minutes ou quelques heures) que les données d’OT, et peuvent souvent être extraites par lots.
Alternatives à la zone de transit
Les données passent des outils d’extraction à l’API d’intégration de CDF. À partir de là, tout se passe sur le cloud. La première étape est la zone de transit de CDF (RAW), où les données tabulaires sont stockées sous leur format d’origine. Cette approche permet de réduire autant que possible la logique dans les outils d’extraction, et de réaliser plusieurs fois des transformations sur les données sur le cloud.
Si vous données ont déjà été diffusées et stockées sur le cloud, par exemple dans un entrepôt de données, vous pouvez alors intégrer les données à la zone de transit de CDF et transformer les données avec les outils de Cognite's. Vous pouvez également transformer les données sur votre cloud et contourner la zone de transit de CDF afin d’intégrer les données directement au modèle de données de CDF.
Transformation des données
L’étape de transformation permet de modeler les données et de les déplacer de la zone de transit au modèle de données de CDF. C’est généralement cette étape qui nécessite le plus de logique de traitement des données.
La transformation des données inclut typiquement l’une ou plusieurs de ces étapes :
- Remodeler les données pour les adapter au modèle de données de
CDF. Par exemple, lire un objet de données dansCDF RAWet le modeler en un événement. - Enrichir les données avec de nouvelles informations. Par exemple, ajouter des données d’autres sources.
- Faire correspondre les données avec d’autres objets de données dans votre recueil.
- Analyser la qualité des données. Par exemple, contrôler si toutes les informations requises sont présentes dans l’objet de données.
Nous recommandons d’utiliser vos outils Extract, Transform, Load (ETL) existants pour transformer les données, mais nous proposons également l’outil CDF Transformation pour des tâches de transformation limitées. CDF Transformations permet d’utiliser des requêtes Spark SQL pour transformer les données depuis votre navigateur.
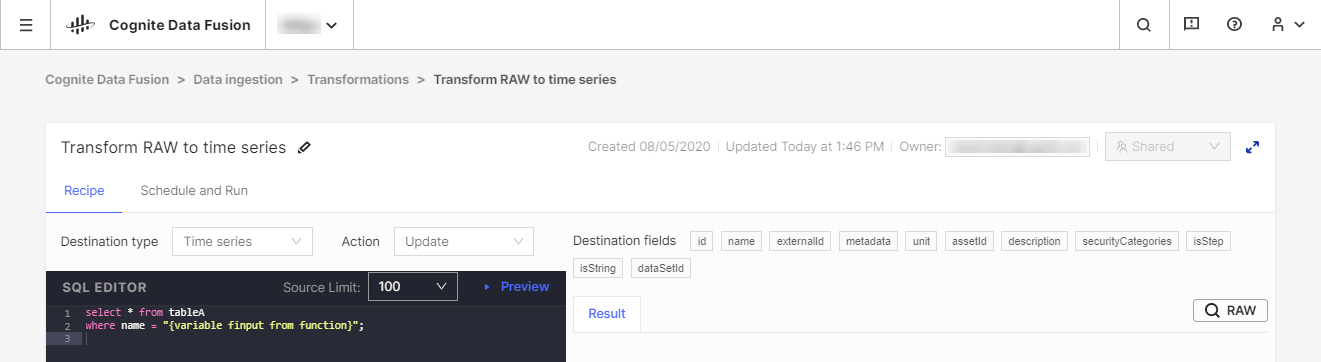
Quel que soit l’outil utilisé, vous transformerez des données du stockage CDF's RAW ou d’un système de transit équivalent vers le modèle de données de Cognite, où vous pourrez encore enrichir les données avec de nouvelles relations pour réaliser des analyses en profondeur et obtenir des informations en temps réel.
Amélioration des données
Un élément très important de vos pipelines d’intégration des données est la contextualisation. Ce processus associe l’apprentissage machine, un puissant moteur de règles et la connaissance du domaine afin de mapper entre elles des ressources de différents systèmes source dans le modèle de données CDF.
La première partie de la contextualisation consiste à s’assurer que chaque entité partage le même identifiant dans CDF, même si elle a différents ID dans les systèmes source. Cette étape est généralement réalisée au stade de la transformation lorsque vous modelez et mettez en correspondance des données entrantes, et les comparez aux ressources existantes de votre recueil.
L’étape suivante du processus de contextualisation consiste à associer des entités entre elles de la même manière qu’elles sont associées dans le monde réelle. Par exemple, un objet dans un modèle 3D peut avoir un ID que vous pouvez mettre en correspondance avec une ressource, et une série temporelle provenant d’un système de surveillance d’instrument peut avoir un autre ID que vous pouvez affecter au même actif.
Les outils de contextualisation interactive dans CDF permettent d’associer l’apprentissage machine, un puissant moteur de règles et la connaissance du domaine afin de mapper entre elles des ressources de différents systèmes source dans le modèle de données CDF.
Vous pouvez, par exemple, créer des schémas d’ingénierie interactifs à partir de fichiers source PDF statiques, et mettre en correspondance des entités afin de configurer, d’automatiser et de valider tous vos pipelines de contextualisation depuis votre navigateur sans avoir de code à écrire.
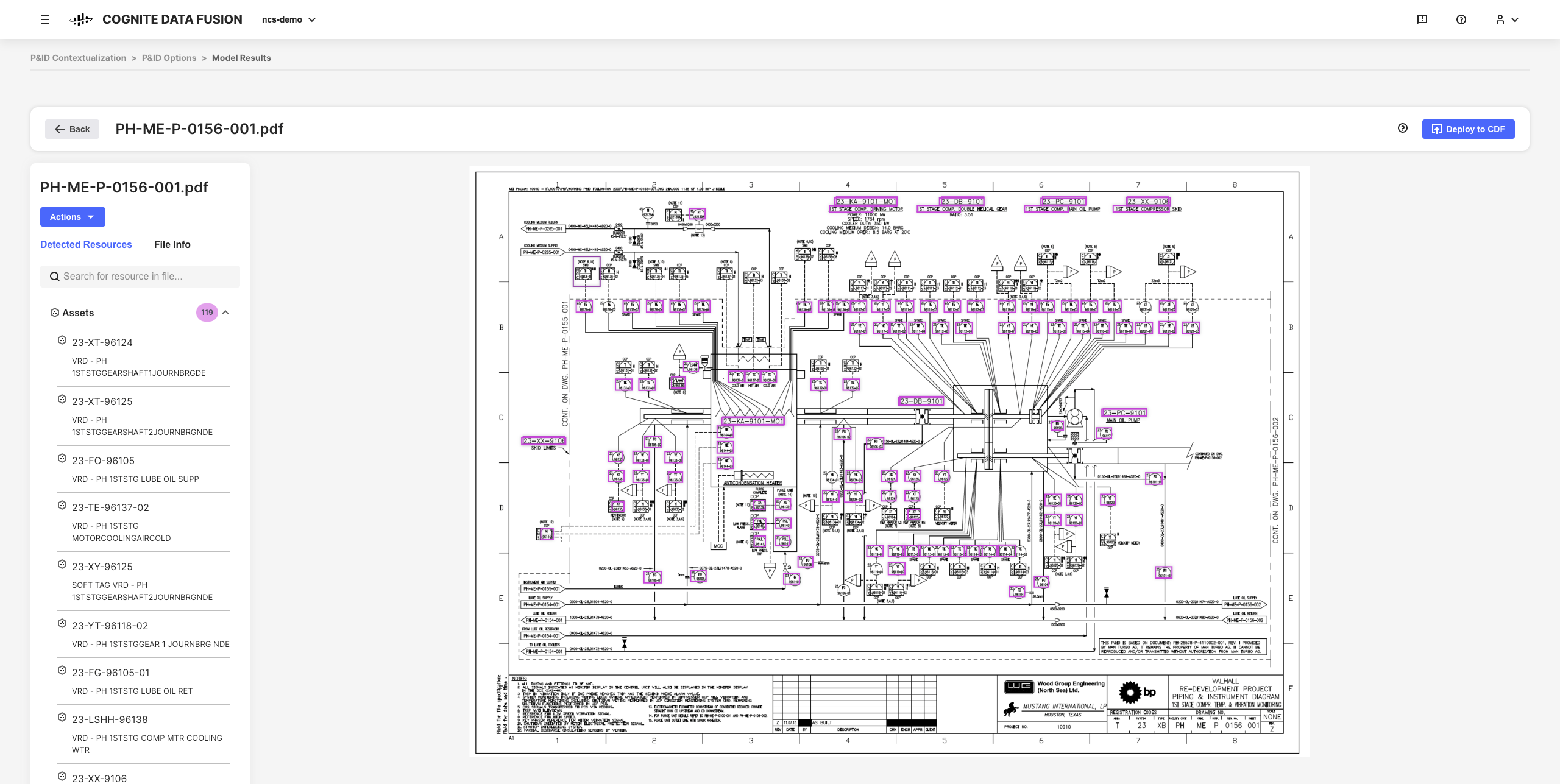
Les données affinées obtenues et les informations utilisées sont la base de la mise à l’échelle de votre implémentation de CDF et de solutions dans votre organisation lorsque vous développez une compréhension plus approfondie de vos données.