Integrar datos
Para analizar y contextualizar sus datos en Cognite Data Fusion (CDF), debe establecer canalizaciones de integración de datos eficientes entre su infraestructura de datos existente y el modelo de datos de CDF.
En CDF, una canalización de integración de datos normalmente incluye pasos para extraer, transformar y contextualizar datos. En esta unidad, veremos más de cerca cada uno de estos pasos.
Para integrar datos en el modelo de datos de CDF, puede usar protocolos e interfaces estándares, por ejemplo PostgreSQL y OPC-UA, así como un extractor y herramientas de transformación de Cognite o de terceros. Las herramientas son esenciales para sus operaciones de datos y le recomendamos que utilice un diseño modular para que sus canalizaciones de integración de datos sean lo más sostenibles posible.
Extraer datos
Las herramientas de extracción se conectan a los sistemas de origen y envían los datos en su formato original al área de preparación. Los extractores de datos funcionan de diferentes maneras. Pueden transmitir datos o extraer datos en lotes para el área de preparación. Además, pueden extraer datos directamente al modelo de datos de CDF con escasa transformación de datos o sin ella.
Con acceso de lectura a las fuentes de datos, puede configurar la integración del sistema para transmitir datos al área de preparación de CDF (RAW), donde los datos pueden ser normalizados y enriquecidos. Somos compatibles con protocolos e interfaces estándares, como PostgreSQL y OPC-UA, para facilitar la integración de datos con sus herramientas ETL y sus soluciones de almacenamiento de datos existentes.
También contamos con extractores hechos a medida para sistemas específicos de la industria y herramientas ETL estándares listas para usar para datos tabulares más tradicionales en bases de datos compatibles con SQL.
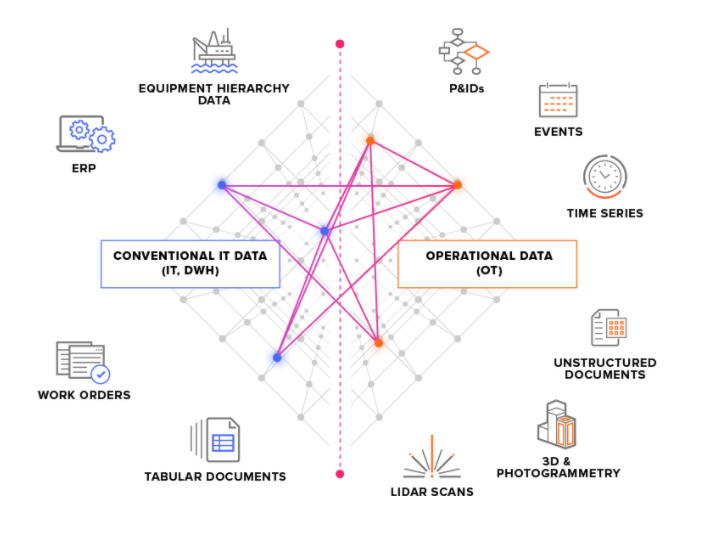
Dividimos los sistemas de origen en dos tipos principales:
-
Sistemas de origen OT: por ejemplo, sistemas de control industrial con datos de series cronológicas. Obtener datos de OT en CDF puede ser crítico en cuanto al tiempo (unos pocos segundos) y, a menudo, es necesario extraer los datos de forma continua.
-
Sistemas de origen de TI: por ejemplo, sistemas ERP, servidores de archivos, bases de datos y sistemas de ingeniería (modelos CAD en 3D). Los datos de TI suelen cambiar con menos frecuencia (minutos u horas) que los datos de OT y, a menudo, se pueden extraer en trabajos por lotes.
Alternativas del área de preparación
Los datos fluyen desde los extractores hacia la API de ingesta de CDF. A partir de aquí, todo está en la nube. La primera parada es el área de preparación de CDF (RAW), donde los datos tabulares se almacenan en su formato original. Este enfoque le permite minimizar la lógica en los extractores, además de ejecutar y volver a ejecutar transformaciones de los datos en la nube.
Si ya tiene sus datos transmitidos y almacenados en la nube, por ejemplo, en un almacén de datos, puede integrar los datos en el área de preparación de CDF desde allí y transformar los datos con herramientas de Cognite's. Como alternativa, puede transformar los datos en su nube y omitir el área de preparación de CDF para integrar los datos directamente en el modelo de datos de CDF.
Transformar datos
El paso de transformación da forma y mueve los datos del área de preparación al modelo de datos de CDF. Este es el paso que, por lo general, aloja la mayor parte de la lógica del procesamiento de datos.
La transformación de datos normalmente incluye uno o más de estos pasos:
- Remodelar los datos para que se ajusten al modelo de datos de
CDF. Por ejemplo, leer un objeto de datos deCDF RAWy convertirlo en un evento. - Enriquecer los datos con más información. Por ejemplo, añadir datos de otras fuentes.
- Emparejar los datos con otros objetos de datos en su colección.
- Analizar la calidad de los datos. Por ejemplo, verificar si toda la información requerida está presente en el objeto de datos.
Recomendamos utilizar sus herramientas existentes de Extracción, Transformación y Carga (ETL) para transformar los datos, pero también ofrecemos la herramienta CDF Transformation como alternativa para trabajos de transformación ligeros. Con CDF Transformations, puede usar consultas Spark SQL para transformar datos desde su navegador.
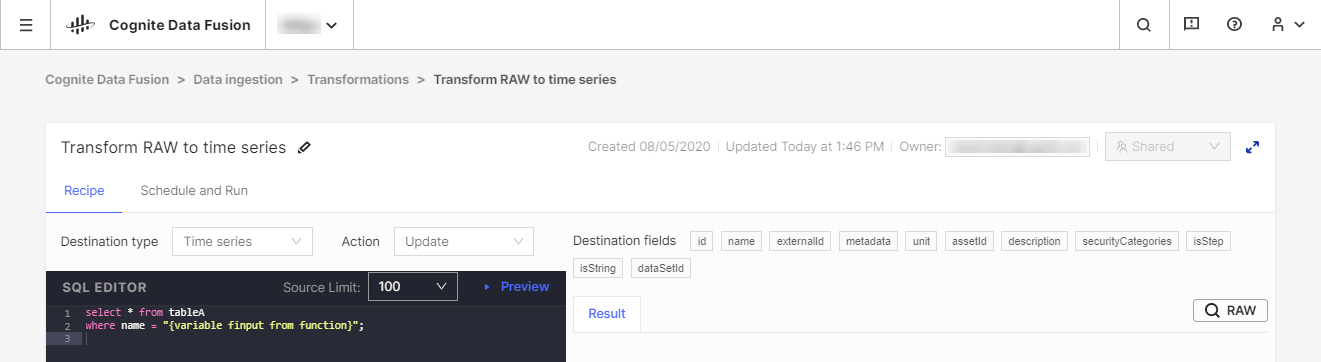
Independientemente de la herramienta que utilice, transformará los datos del almacenamiento CDF's RAW o un sistema de preparación equivalente al modelo de datos de Cognite, donde podrá enriquecer aún más los datos con otras relaciones para obtener análisis detallados y conocimiento en tiempo real.
Mejorar datos
Una pieza muy importante de las canalizaciones de integración de sus datos es la contextualización. Este proceso combina aprendizaje automático, un potente motor de reglas y conocimiento del dominio para asignar recursos de diferentes sistemas de origen entre sí en el modelo de datos de CDF.
La primera parte de la contextualización sirve para garantizar que cada entidad única comparta el mismo identificador en CDF, incluso si tienen ID diferentes en los sistemas de origen. Este paso se realiza principalmente durante la etapa de transformación cuando moldea y combina los datos entrantes y los compara con los recursos existentes en su colección.
El siguiente paso en el proceso de contextualización es asociar entidades entre sí de la misma forma en que se relacionan en el mundo real. Por ejemplo, es posible que un objeto dentro de un modelo 3D tenga una ID que puede asignar a un activo, y que una serie cronológica de un sistema de monitoreo de instrumentos tenga otra ID que puede asignar al mismo activo.
Las herramientas interactivas de contextualización en CDF le permiten combinar el aprendizaje automático, un potente motor de reglas y experiencia en el dominio para mapear recursos de diferentes sistemas de origen entre sí en el modelo de datos CDF.
Por ejemplo, puede crear diagramas de ingeniería interactivos a partir de archivos de origen PDF estáticos y hacer coincidir entidades para configurar, automatizar y validar todas sus canalizaciones de contextualización desde su navegador sin tener que escribir ningún código.
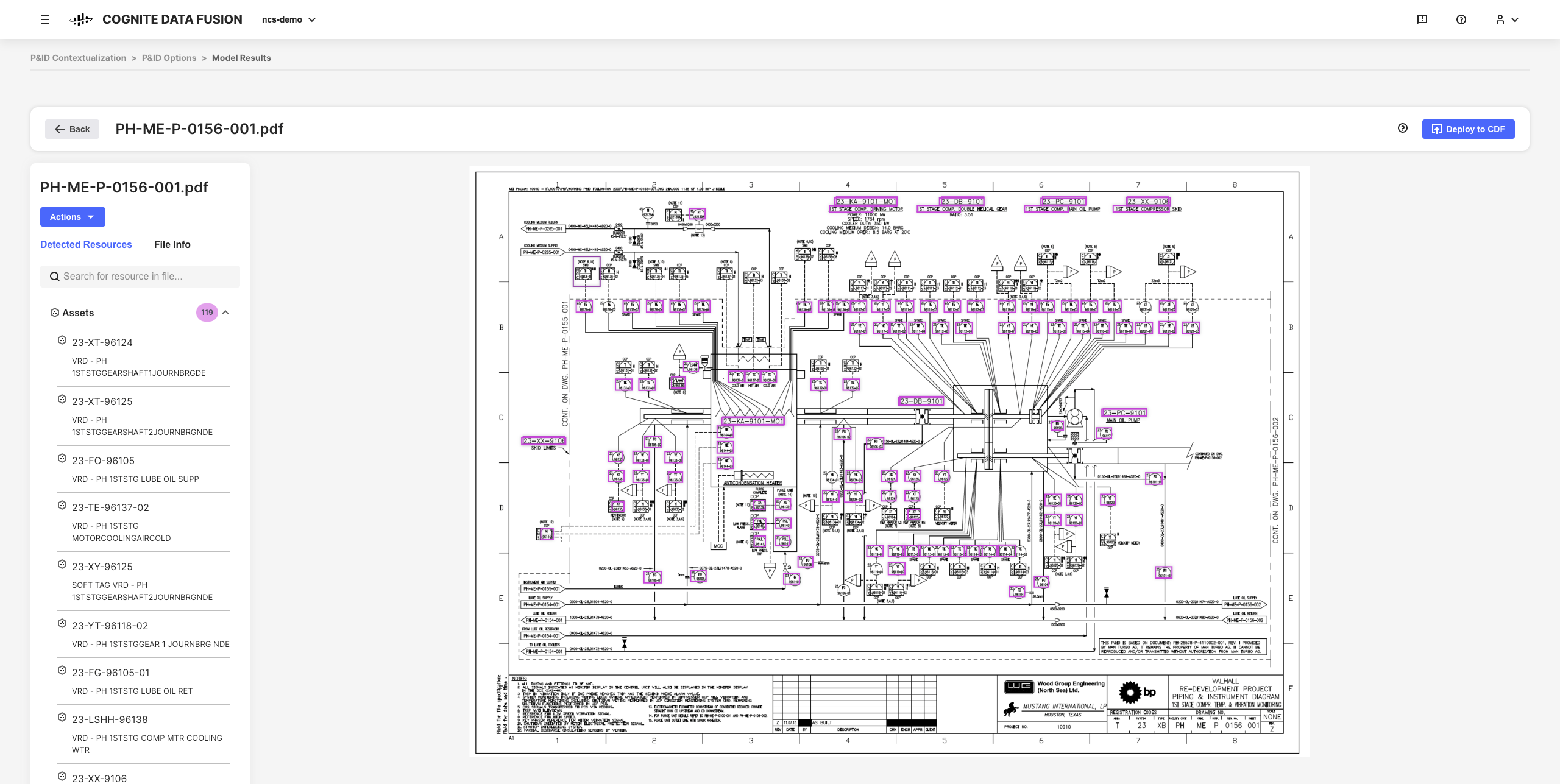
Los datos refinados resultantes y los conocimientos inferidos son la base para escalar la implementación y soluciones CDF en toda su organización, a medida que adquiere una comprensión más profunda de sus datos.