Integrazione dei dati
Per analizzare e contestualizzare i dati in Cognite Data Fusion (CDF), è necessario definire pipeline di integrazione dei dati efficienti tra l'infrastruttura dati esistente e il modello dati di CDF.
In CDF, una pipeline di integrazione dei dati include in genere passaggi per estrarre, trasformare e contestualizzare i dati. In questa unità analizzeremo nel dettaglio ognuno di questi passaggi.
Per integrare i dati nel modello dati di CDF, è possibile utilizzare le interfacce e i protocolli standard come PostgreSQL e OPC-UA nonché strumenti di trasformazione ed estrattori di Cognite o terze parti. Gli strumenti sono essenziali per le operazioni sui dati, pertanto è consigliabile utilizzare un design modulare per le pipeline di integrazione dei dati per renderle il più gestibili possibile.
Estrazione dei dati
Gli strumenti di estrazione si connettono ai sistemi di origine ed eseguono il push dei dati nel formato originale nell'area di gestione temporanea. Gli strumenti di estrazione dei dati possono funzionare in modalità diverse. Possono eseguire lo streaming dei dati o estrarli in batch nell'area di gestione temporanea. Possono anche estrarre i dati direttamente nel modello dati di CDF con o senza trasformazione dei dati.
Con l'accesso in lettura alle origini dati, è possibile impostare l'integrazione di sistemi per eseguire lo streaming dei dati nell'area di gestione temporanea di CDF (RAW), dove i dati possono essere normalizzati e arricchiti. Supportiamo interfacce e protocolli standard come PostgreSQL e OPC-UA per agevolare l'integrazione dei dati con strumenti ETL esistenti e soluzioni di data warehouse.
Disponiamo anche di estrattori personalizzati per sistemi specifici del settore e di strumenti ETL standard pronti all'uso per dati in formato tabulare più tradizionali in database compatibili con SQL.
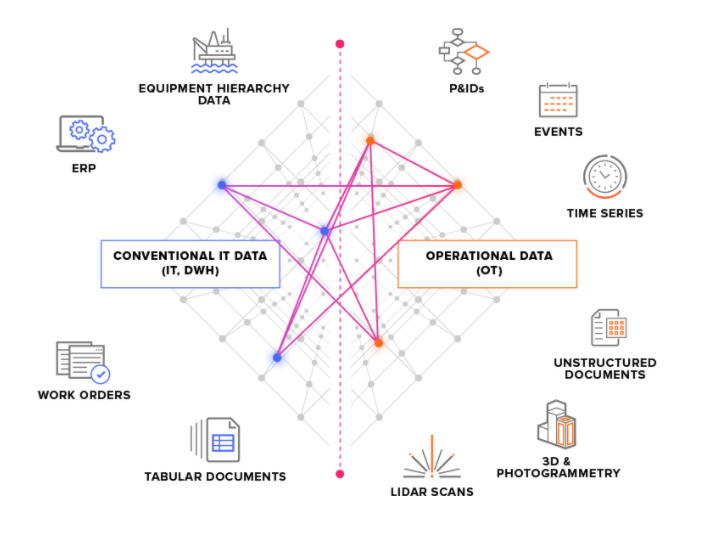
Dividiamo i sistemi di origine in due tipi principali:
-
Sistemi di origine OT: ad esempio sistemi di controllo industriali con dati delle serie temporali. Il recupero dei dati OT in CDF può essere time-critical (alcuni secondi) e i dati devono spesso essere estratti con continuità.
-
Sistemi di origine IT: ad esempio sistemi ERP, file server, database e sistemi tecnici (modelli CAD 3D). In genere, i dati IT cambiano con minore frequenza (minuti o ore) rispetto ai dati OT e spesso possono essere estratti in processi batch.
Alternative all'area di gestione temporanea
I dati vengono trasmessi in flussi dagli estrattori all'API di inserimento di CDF. Da qui in poi, tutto risiede nel cloud. La prima tappa è l'area di gestione temporanea di CDF (RAW), dove i dati tabulari sono archiviati nel formato originale. Questo approccio consente di ridurre al minimo la logica negli estrattori e di eseguire e rieseguire trasformazioni sui dati nel cloud.
Se lo streaming dei dati è terminato e questi sono archiviati nel cloud, ad esempio in un data warehouse, è possibile integrarli nell'area di gestione temporanea di CDF e trasformarli con gli strumenti di Cognite's. In alternativa, è possibile trasformare i dati nel cloud e ignorare l'area di gestione temporanea di CDF per integrare i dati direttamente nel modello dati di CDF.
Trasformazione dei dati
Il passaggio di trasformazione rimodella i dati e li sposta dall'area di gestione temporanea al modello dati di CDF. Si tratta del passaggio che ospita in genere la maggior parte della logica di elaborazione dei dati.
La trasformazione dei dati include in genere uno o più di questi passaggi:
- Rimodellare i dati per adattarli al modello dati di
CDF. Ad esempio, leggere un oggetto dati daCDF RAWe modellarlo in un evento. - Arricchimento dei dati con maggiori informazioni. Ad esempio, aggiungere dati da altre origini.
- Abbinamento dei dati ad altri oggetti dati della raccolta.
- Analisi della qualità dei dati. Ad esempio, verificare se tutte le informazioni necessarie sono presenti nell'oggetto dati.
È consigliabile utilizzare gli strumenti ETL (Extract, Transform, Load) esistenti per trasformare i dati, anche se è disponibile lo strumento CDF Transformation come alternativa per processi di trasformazione poco voluminosi. Con CDF Transformations, è possibile utilizzare le query Spark SQL per trasformare i dati dall'interno del browser.
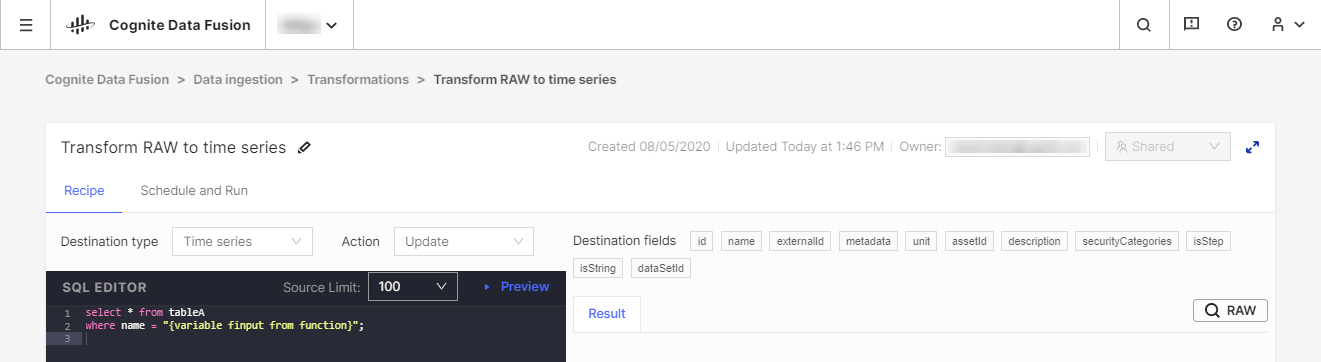
Indipendentemente dallo strumento utilizzato, si trasformeranno i dati dallo spazio di archiviazione CDF's RAW o da un sistema di gestione temporanea equivalente nel modello dati di Cognite, dove è possibile arricchire ulteriormente i dati con altre relazioni per analisi approfondite e informazioni in tempo reale.
Arricchimento dei dati
Un aspetto importante delle pipeline di integrazione dei dati è la contestualizzazione. Questo processo combina la tecnologia machine learning, un potente motore di regole e conoscenze del dominio per mappare tra loro le risorse da sistemi di origine diversi nel modello dati di CDF.
La prima parte della contestualizzazione è garantire che ogni entità univoca condivida lo stesso identificatore in CDF, anche se ha ID diversi nei sistemi di origine. Questo passaggio viene eseguito per lo più durante la fase di trasformazione quando si modellano e abbinano i dati in arrivo e li si confrontano con risorse esistenti nella raccolta.
Il passaggio successivo del processo di contestualizzazione consiste nell'associare entità tra loro nello stesso modo in cui sono correlate nel mondo reale. Ad esempio, un oggetto all'interno di un modello 3D potrebbe avere un ID abbinabile a un asset e una serie temporale da un sistema di monitoraggio strumento può avere un altro ID assegnabile allo stesso asset.
Gli strumenti di contestualizzazione interattivi di CDF consentono di combinare la tecnologia machine learning, un potente motore di regole e la conoscenza del dominio per abbinare le risorse da sistemi di origine diversi tra loro nel modello dati di CDF.
Ad esempio, è possibile creare diagrammi tecnici interattivi da file di origine PDF statici e abbinare entità per impostare, automatizzare e convalidare tutte le pipeline di contestualizzazione dal browser senza dover scrivere codice.
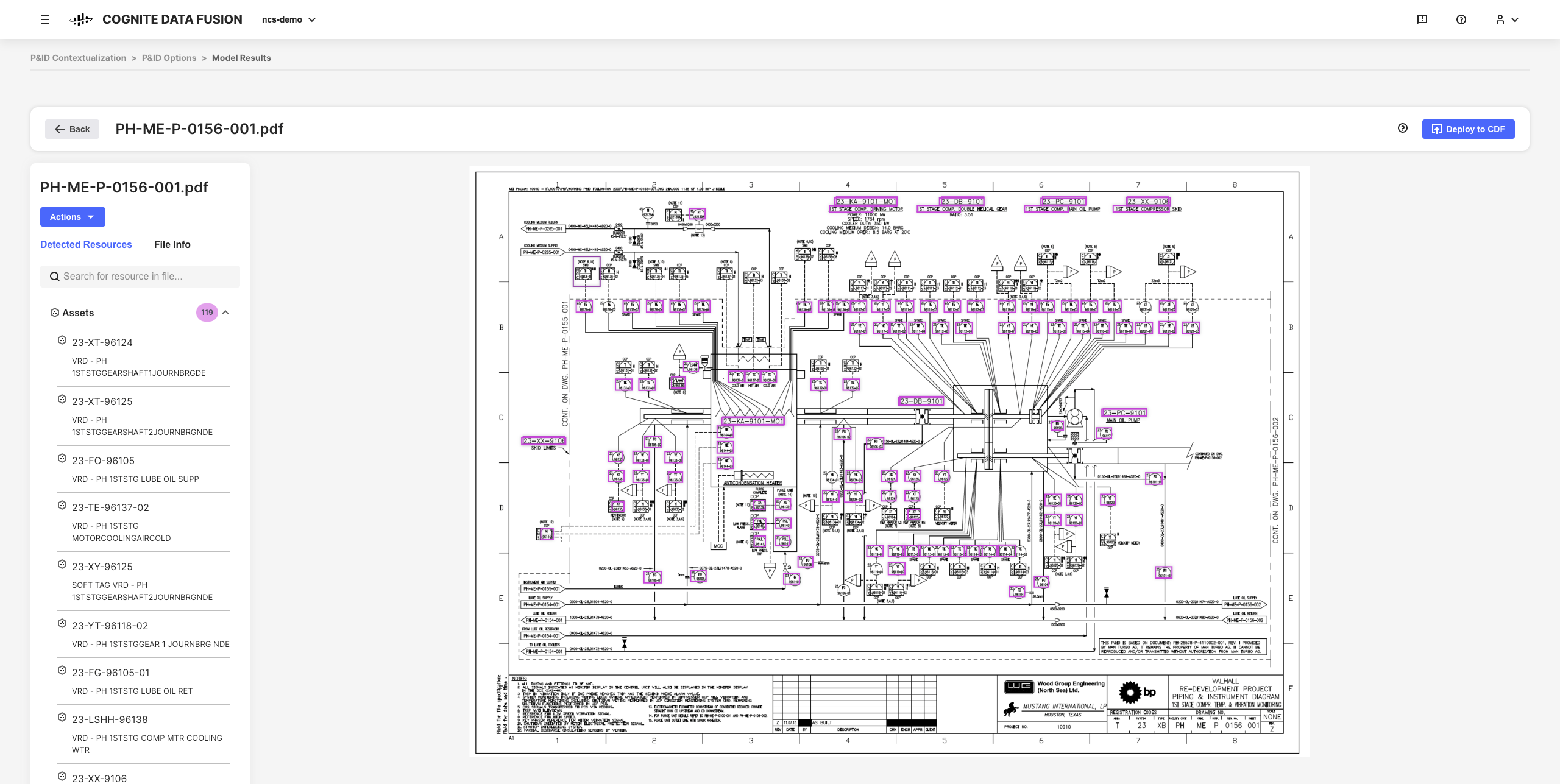
I dati ridefiniti risultanti e le informazioni dettagliate dedotte sono le basi per scalare le soluzioni e l'implementazione di CDF nell'organizzazione man mano che si sviluppa una conoscenza più approfondita dei dati.