Integrar dados
Para analisar e contextualizar seus dados no Cognite Data Fusion (CDF), você precisa estabelecer pipelines de integração de dados eficientes entre sua infraestrutura de dados existente e o modelo de dados do CDF.
No CDF, um pipeline de integração de dados geralmente inclui etapas para extrair, transformar e contextualizar dados. Nesta unidade, vamos descrever em mais detalhes cada uma dessas etapas.
Para integrar dados no modelo de dados do CDF, você pode usar protocolos e interfaces padrão como PostgreSQL e OPC-UA, além de ferramentas de extração e transformação da Cognite ou de terceiros. As ferramentas são essenciais para suas operações de dados, e recomendamos que você use um design modular para seus pipelines de integração de dados para facilitar ao máximo a manutenção deles.
Extrair dados
As ferramentas de extração se conectam aos sistemas de origem e enviam os dados em seu formato original para a área de preparação. Os extratores de dados operam em modos diferentes. Eles podem transmitir dados ou extrair dados em lotes para a área de preparação. Além disso, eles podem extrair dados diretamente para o modelo de dados do CDF com pouca ou nenhuma transformação de dados.
Com acesso de leitura às fontes de dados, você pode configurar a integração do sistema para transmitir dados para a área de preparação do CDF (RAW), onde os dados podem ser normalizados e enriquecidos. Nossa solução é compatível com protocolos e interfaces padrão, como PostgreSQL e OPC-UA, para facilitar a integração de dados com suas ferramentas de ETL e soluções de data warehouse existentes.
Também temos extratores personalizados para sistemas específicos do setor e ferramentas padrão de ETL prontas para uso com dados tabulares mais tradicionais em bancos de dados compatíveis com SQL.
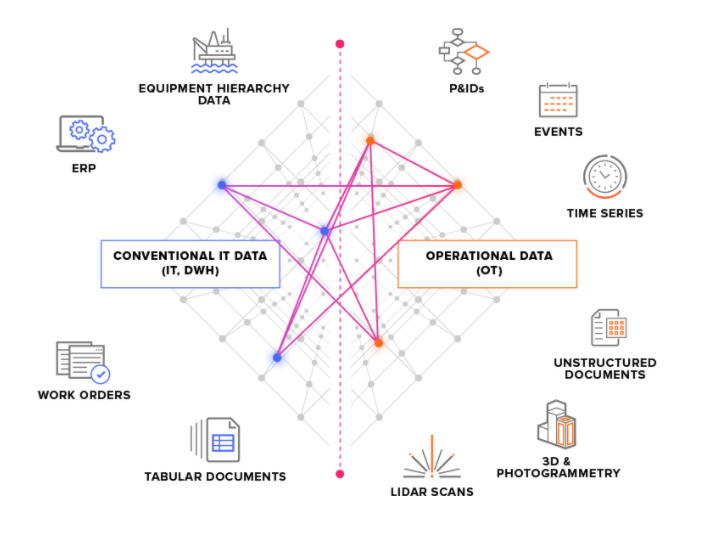
Dividimos os sistemas de origem em dois tipos principais:
-
Sistemas de origem de TO: por exemplo, sistemas de controle industrial com dados de séries temporais. A obtenção de dados de TO no CDF pode ser crítica em termos de tempo (alguns segundos) e os dados geralmente precisam ser extraídos continuamente.
-
Sistemas de origem de TI: por exemplo, sistemas ERP, servidores de arquivos, bancos de dados e sistemas de engenharia (modelos CAD 3D). Os dados de TI geralmente mudam com menos frequência (minutos ou horas) do que os dados de TO e podem ser extraídos com frequência em tarefas em lote.
Alternativas de área de preparação
Os dados são transmitidos dos extratores para a API de ingestão do CDF. Depois disso, tudo estará na nuvem. A primeira parada é a área de preparação do CDF (RAW), onde os dados tabulares são armazenados no formato original. Essa abordagem permite minimizar a lógica nos extratores e executar e reexecutar transformações nos dados na nuvem.
Se os seus dados já foram transmitidos e armazenados na nuvem, por exemplo, em um data warehouse, você pode integrar os dados na área de preparação do CDF e, de lá, transformar os dados com ferramentas da Cognite's. Como alternativa, você pode transformar os dados em sua nuvem e ignorar a área de preparação do CDF para integrar os dados diretamente no modelo de dados do CDF.
Transformar dados
A etapa transformar molda e move os dados da área de preparação para o modelo de dados do CDF. Esta é a etapa que geralmente hospeda a maior parte da lógica de processamento de dados.
A transformação de dados normalmente inclui uma ou mais destas etapas:
- Remodelar os dados para que caibam no modelo de dados do
CDF. Por exemplo, leia um objeto de dados doCDF RAWe transforme-o em um evento. - Enriquecer os dados com mais informações. Por exemplo, adicione dados de outras fontes.
- Combinar os dados com outros objetos de dados em sua coleção.
- Analisar a qualidade dos dados. Por exemplo, verifique se todas as informações necessárias estão presentes no objeto de dados.
Recomendamos o uso de suas ferramentas de extração, transformação e carregamento (ETL) existentes para transformar os dados. Mas também oferecemos a ferramenta CDF Transformation como uma alternativa para tarefas de transformação leves. Com o CDF Transformations, você pode usar consultas SQL do Spark para transformar dados no seu navegador.
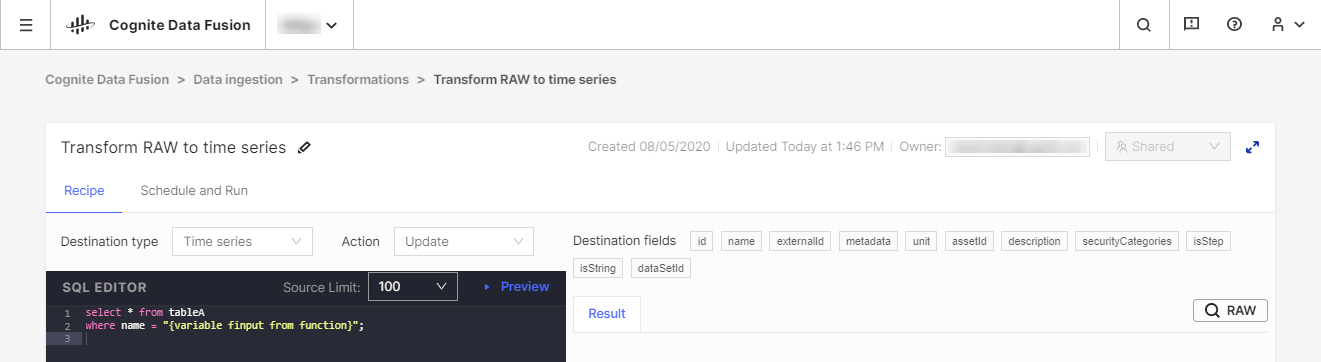
Independentemente da ferramenta que usar, você transformará os dados do armazenamento do CDF's RAW ou de um sistema de preparação equivalente no modelo de dados da Cognite, podendo enriquecer ainda mais os dados com mais relações para análises aprofundadas e insights em tempo real.
Aprimorar dados
Uma parte muito importante de seus pipelines de integração de dados é a contextualização. Esse processo combina aprendizado de máquina, um poderoso mecanismo de regras e conhecimento de domínio para mapear recursos de diferentes sistemas de origem entre si no modelo de dados do CDF.
A primeira parte da contextualização é garantir que cada entidade única compartilhe o mesmo identificador no CDF, mesmo que tenha IDs diferentes nos sistemas de origem. Essa etapa é executada principalmente durante a fase de transformação, quando você molda e corresponde os dados recebidos e os compara com os recursos existentes em sua coleção.
A próxima etapa no processo de contextualização é associar as entidades entre si da mesma forma que se relacionam no mundo real. Por exemplo, um objeto dentro de um modelo 3D pode ter uma ID que você pode mapear para um ativo, e uma série temporal de um sistema de monitoramento de instrumentos pode ter outra ID que você pode atribuir ao mesmo ativo.
As ferramentas interativas de contextualização no CDF permitem que você combine aprendizado de máquina, um poderoso mecanismo de regras e conhecimento de domínio para mapear recursos de diferentes sistemas de origem entre si no modelo de dados do CDF.
Por exemplo, você pode criar diagramas de engenharia interativos a partir de arquivos PDF de origem e estáticos e combinar entidades para configurar, automatizar e validar todos os seus pipelines de contextualização em seu navegador sem precisar escrever nenhum código.
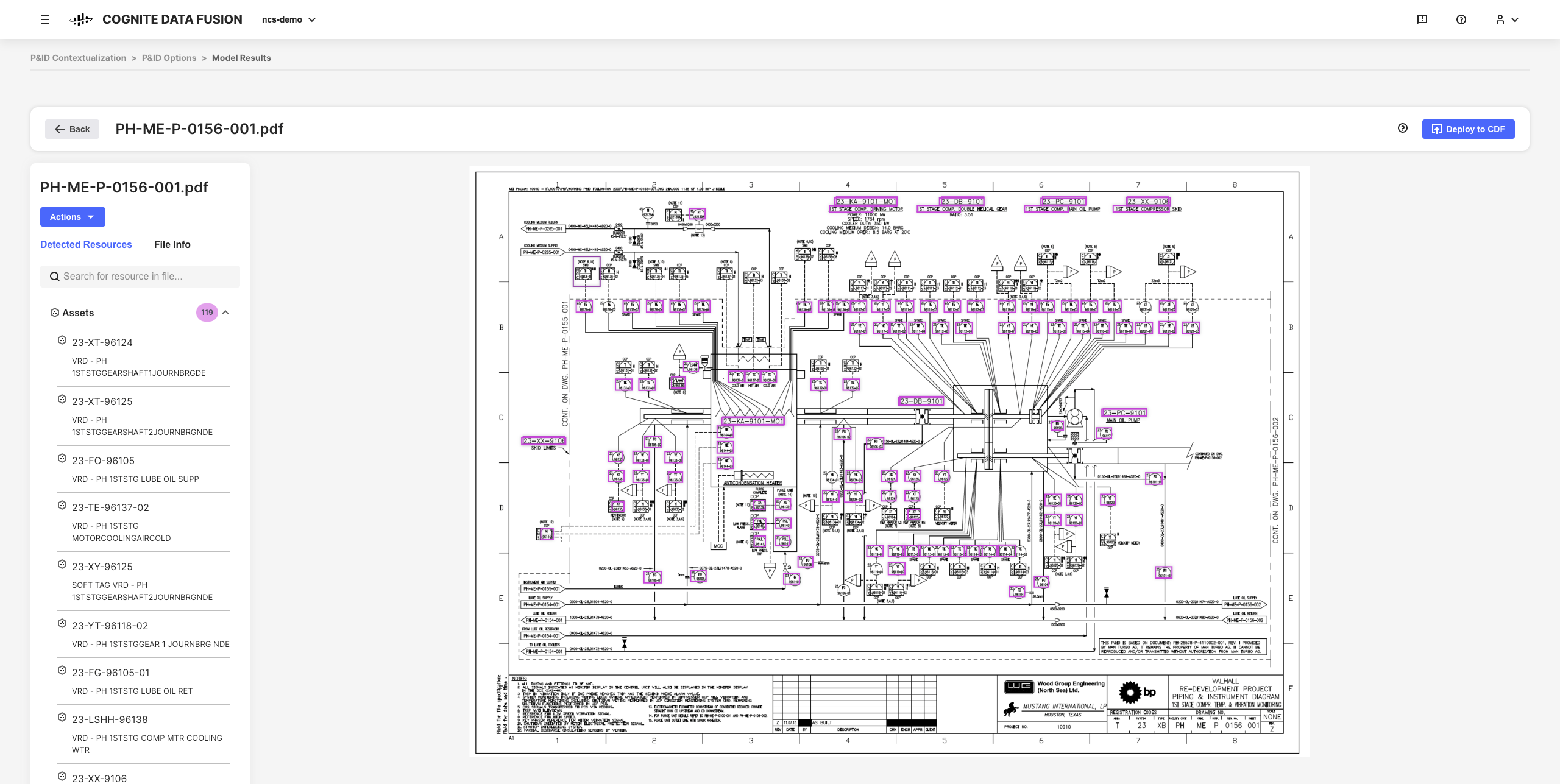
Os dados refinados resultantes e os insights inferidos são a base para dimensionar sua implementação e soluções do CDF em toda a organização, à medida que você compreende melhor seus dados.