datu integrēšana
Lai analizētu un kontekstualizētu datus platformā Cognite Data Fusion (CDF), ir jāizveido efektīvi datu integrēšanas kanāli starp esošo datu infrastruktūru un CDF datu modeli.
Platformā CDF datu integrēšanas kanāls parasti ietver datu izvilkšanas, transformēšanas un kontekstualizēšanas posmus. Šajā sadaļā mēs sīkāk izpētīsim katru no šiem posmiem.
Lai integrētu datus CDF datu modelī, var izmantot standarta protokolus un saskarnes, piemēram, PostgreSQL un OPC-UA, kā arī Cognite vai trešo pušu izvilcēju un transformēšanas rīkus. Rīkiem ir būtiska loma jūsu datu operācijās un ieteicams datu integrēšanas kanāliem izmantot modulāru uzbūvi, lai tos varētu pēc iespējas vieglāk uzturēt.
Datu izvilkšana
Izvilkšanas rīki veido savienojumu ar avota sistēmām un oriģinālformātā aizgādā datus izstādīšanas apgabalā. Datu izvilcēji darbojas dažādos režīmos. Tie var straumēt datus vai izvilkt datus izstādīšanas apgabalā pakešu veidā. Tie var arī uzreiz izvilkt datus CDF datu modelī ar nelielu datu transformēšanu vai bez tās.
Ar lasīšanas piekļuvi datu avotiem var iestatīt sistēmas integrēšanu, lai straumētu datus CDF izstādīšanas apgabalā (RAW), kur datus var normalizēt un uzlabot. Mēs atbalstām standarta protokolus un saskarnes, piemēram, PostgreSQL un OPC-UA, lai sekmētu datu integrēšanu jūsu esošajos ETL rīkos un datu noliktavu risinājumos.
Tradicionālākiem tabulārajiem datiem datu bāzēs, kas ir saderīgas ar SQL, mēs nodrošinām arī izvilcējus, kas ir īpaši izstrādāti specifiskām nozaru sistēmām un standarta plašpatēriņa ETL rīkiem.
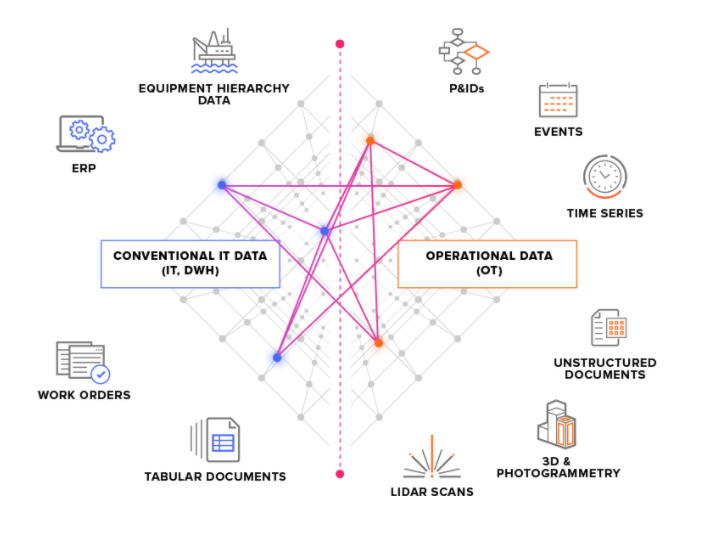
Mēs iedalām avota sistēmas divos galvenajos veidos:
-
OT (ekspluatācijas tehnoloģiju) avota sistēmas, piemēram, rūpnieciskās vadības sistēmas ar laika rindu datiem. OT datu pārnešana uz CDF reizēm var būt nepieciešama steidzami (dažu sekunžu laikā), un bieži ir nepieciešams nodrošināt nepārtrauktu datu izvilkšanu;
-
IT avota sistēmas, piemēram, ERP sistēmas, failu serveri, datu bāzes un tehniskās sistēmas (3D datorizētās projektēšanas modeļi). IT dati parasti mainās retāk (biežums ir mērāms minūtēs vai stundās) nekā ekspluatācijas tehnoloģiju dati, un tos bieži var izvilkt, izpildot pakešuzdevumus.
Alternatīvas izstādīšanas apgabalam
Dati plūst no izvilcējiem uz CDF uzņemšanas API. No šī brīža viss notiek mākonī. Pirmā pieturvieta ir CDF izstādīšanas apgabals (RAW), kur tabulārie dati tiek glabāti to oriģinālformātā. Šī pieeja ļauj vienkāršot izvilcēju loģiku, kā arī izpildīt un atkārtoti izpildīt datu transformēšanu mākonī.
Ja jūsu dati jau tiek straumēti un glabāti mākonī, piemēram, datu noliktavā, varat tos integrēt CDF izstādīšanas apgabalā no mākoņa un transformēt, izmantojot Cognite's rīkus. Varat datus transformēt arī mākonī, apejot CDF izstādīšanas apgabalu, tiešā veidā integrējot datus CDF datu modelī.
Datu transformēšana
Transformēšanas posmā dati tiek strukturēti un pārvietoti no izstādīšanas apgabala uz CDF datu modeli. Šajā posmā parasti tiek izpildīta lielākā datu apstrādes loģikas daļa.
Datu transformēšana parasti ietver vienu vai vairākus no tālāk minētajiem posmiem.
- Datu pārveidošana, pielāgojot tos
CDFdatu modelim. Kā piemēru var minēt datu objekta nolasīšanu noCDF RAWformāta un pārveidošanu par notikumu. - Datu uzlabošana, papildinot tos ar jaunu informāciju. Kā piemēru var minēt datu pievienošanu no citiem avotiem.
- Datu saskaņošana ar citiem datu objektiem kolekcijā.
- Datu kvalitātes analīze. Piemēram, pārbaudiet, vai datu objektā ir visa nepieciešamā informācija.
Iesakām datu transformēšanai izmantot visus jūsu rīcībā esošos izvilkšanas, transformēšanas un ielādes (ETL) rīkus, bet mēs piedāvājam arī rīku CDF Transformation kā alternatīvu risinājumu efektīvai transformēšanas uzdevumu izpildei. Rīku CDF Transformations var izmantot Spark SQL vaicājumiem datu transformēšanai pārlūkā.
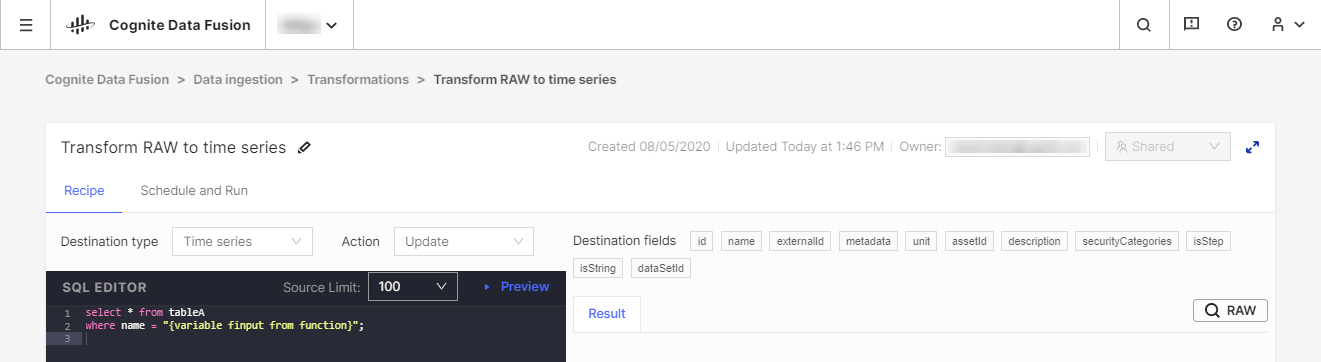
Neatkarīgi no izmantotā rīka jūs transformēsiet datus no CDF's RAW vai līdzīgas izstādīšanas sistēmas krātuves formāta Cognite datu modeļa formātā, kur varat uzlabot datus, pievienojot jaunas saiknes padziļinātai analītikai un reāllaika secinājumiem.
Datu uzlabošana
Datu integrēšanas kanālu kritiskas nozīmes elements ir kontekstualizēšana. Šis process apvieno mašīnmācīšanos, efektīvu kārtulu programmu un specializētas zināšanas, lai CDF datu modelī savstarpēji kartētu resursus no dažādām avota sistēmām.
Šīs kontekstualizēšanas pirmais posms ir nodrošināt, lai katrai unikālajai entītijai platformā CDF būtu viens un tas pats identifikators pat tad, ja avota sistēmās tam ir atšķirīgi identifikatori. Šo posmu parasti izpilda transformēšanas posma laikā, kad tiek veikta ienākošo datu strukturizēšana, saskaņošana un salīdzināšana ar jūsu kolekcijā esošajiem resursiem.
Nākamais kontekstualizēšanas procesa posms ir entītiju savstarpējā saistīšana atbilstoši to reālajai fiziskajai saiknei. Piemēram, objektam 3D modelī var būt identifikators, kuru varat kartēt ar aktīvu, un laika rindai no instrumentu pārraudzības sistēmas var būt cits identifikators, kuru varat piešķirt šim pašam aktīvam.
Interaktīvie kontekstualizēšanas rīki platformā CDF ļauj izmantot mašīnmācīšanās, efektīvas kārtulu programmas un specializēto zināšanu kombināciju, lai savstarpēji kartētu resursus no dažādām avota sistēmām CDF datu modelī.
Piemēram, varat veidot interaktīvus shematiskos attēlus no statiskiem PDF avota failiem un salāgot ar tiem entītijas, lai izveidotu, automatizētu un validētu visus savus kontekstualizēšanas kanālus savā pārlūkā, neveicot kodēšanu.
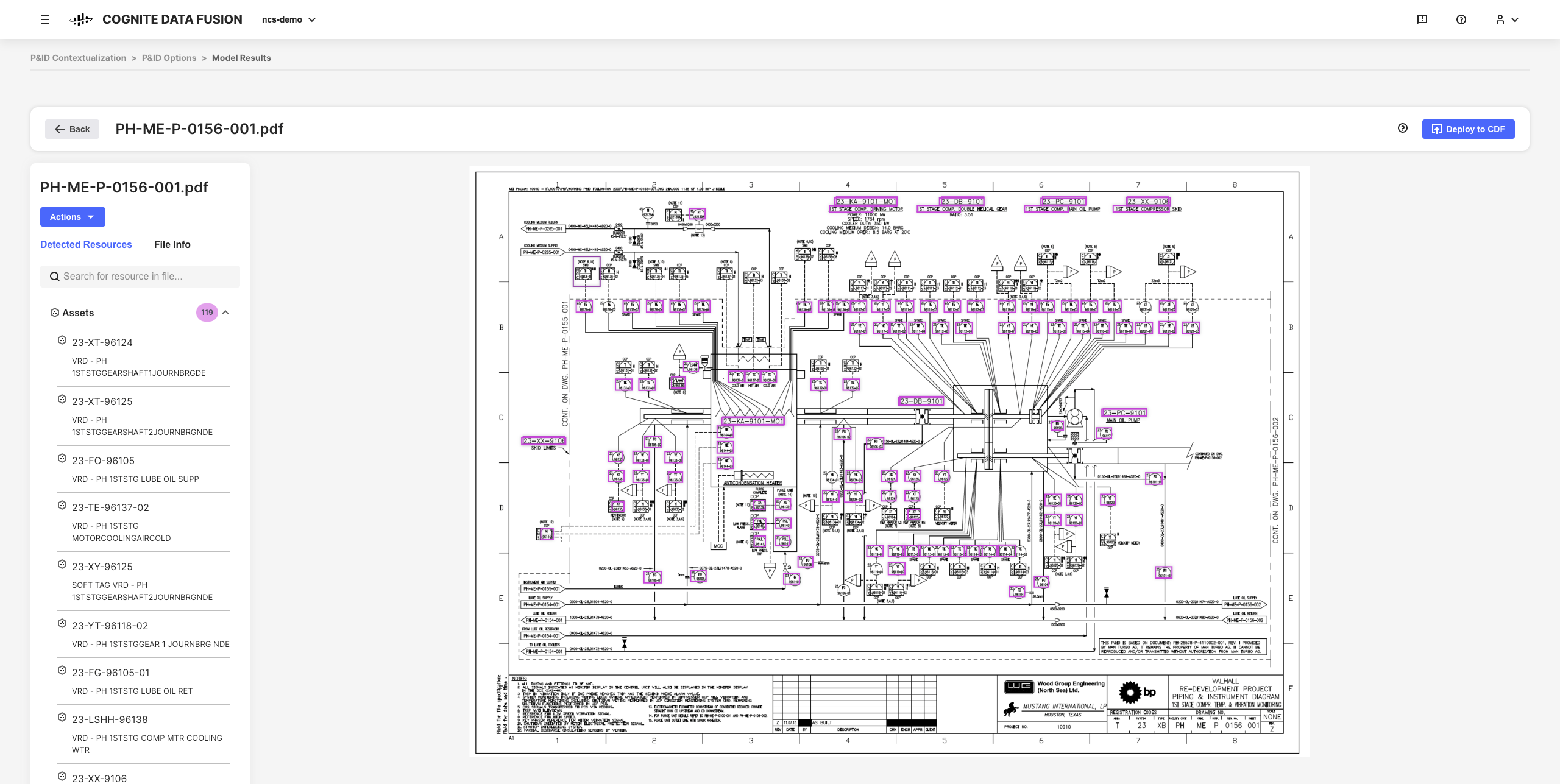
Iegūtie optimizētie dati un ieskati ir pamats CDF risinājumu izvēršanai visā organizācijā, tādējādi gūstot padziļinātu izpratni par datiem.