集成数据
为了在 Cognite Data Fusion (CDF) 中分析并将数据上下文化,你需要在现有数据基础设施和 CDF 数据模型之间建立有效的数据集成管道。
在 CDF 中,数据集成管道通常包括提取、转换和上下文化数据的步骤。在本单元中,我们将仔细了解每个步骤。
要将数据集成到 CDF 数据模型中,你可以使用标准协议和接口,例如 PostgreSQL 和 OPC-UA 以及 Cognite 或第三方提取器和转换工具。这些工具对数据操作至关重要,因此我们建议你对数据集成管道使用模块化设计,以使其尽可能便于维护。
提取数据
提取工具连接来源系统,并使用其原始格式将数据推送到数据准备区。数据提取器可在不同模式下运行。它们可以流式传输数据,或将数据批量提取到数据准备区。另外,它们还可以直接将数据提取到 CDF 数据模型,几乎或完全不需要数据转换。
如果拥有数据源的读取权限,你可以设置系统集成以将数据流式传输到 CDF 数据准备区 (RAW),从中可以对数据进行归一化和扩充。我们支持诸如 PostgreSQL 和 OPC-UA 等标准协议和接口,以便于数据与现有 ETL 工具和数据仓库解决方案集成。
我们还有为行业特定系统定制的提取器,以及适用于 SQL 兼容型数据库中更加传统的表格数据的标准现成 ETL 工具。
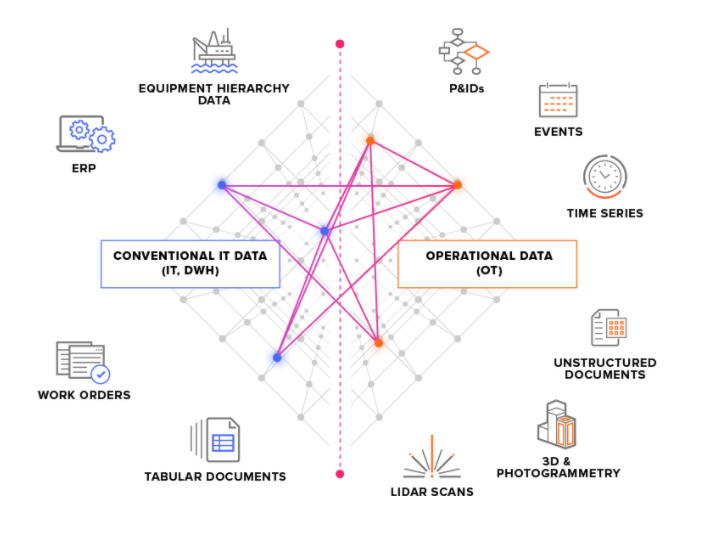
我们将来源系统分为两个主要类型:
-
OT 来源系统 - 例如,包含时间序列数据的工业控制系统。OT 数据进入 CDF 可能为实时性(只需几秒钟),并且经常需要连续提取数据。
-
IT 来源系统 - 例如 ERP 系统、文件服务器、数据库和工程系统(3D CAD 模型)。IT 数据的更改频率通常低于 OT 数据(数分钟或数小时),并且经常可能在批量作业中提取。
数据准备区备选
数据从提取器流进 CDF 引入 API。从这里开始,一切都存在于云端。第一站是** CDF 数据准备区** (RAW),从中使用原始格式存储表格数据。通过这种方法,你可以最大限度地减少提取器中的逻辑,并在云端运行和重新运行数据转换。
如果你已将数据流式传输并存储到云端(例如在数据仓库中),则可从中将数据集成到 CDF 数据准备区,并使用 Cognite's 工具转换数据。或者,你也可以在云端转换数据,并绕过 CDF 数据准备区直接将数据集成到 CDF 数据模型中。
转换数据
转换步骤调整数据并将其从数据准备区移动到 CDF 数据模型中。此步骤通常涉及大部分数据处理逻辑。
数据转换通常包括下列一个或多个步骤:
- 重新调整数据以适应
CDF数据模型。例如,从CDF RAW读取数据对象并将其调整为事件。 - 扩充数据,使其包含更多信息。例如,从其他来源添加数据。
- 匹配数据与集合中的其他数据对象。
- 分析数据的质量。例如,检查数据对象中是否存在所有必需的信息。
我们建议使用现有的提取、转换、加载 (ETL) 工具来转换数据,但是我们也提供了 CDF Transformation 工具作为轻量级转换任务的备选方案。通过 CDF Transformations,你可以使用 Spark SQL 查询从浏览器转换数据。
无论使用哪种工具,你都将来自 CDF's RAW 存储或同等数据准备系统的数据转换到 Cognite 数据模型中,从中你可以进一步为数据扩充更多关系,以便进行深入分析并获得实时洞察。
增强数据
数据集成管道中最重要的部分是上下文化。此流程结合了机器学习、强大的规则引擎和域知识,以在 CDF 数据模型中相互映射不同来源系统中的资源。
上下文化流程的第一步是确保每个唯一实体在 CDF 中都使用相同的标识符,即使它们在来源系统中拥有不同的 ID。此步骤主要在转换阶段执行,在此阶段中你调整和匹配传入数据,并将其与集合中的现有资源进行比较。
上下文化流程的下一个步骤是采用实体在现实中产生联系的方式,将实体相互关联。例如,3D 模型中的对象可能拥有你可映射到资产的 ID,而来自仪表监控系统的时间序列可能拥有你可分配给相同资产的另一个 ID。
CDF 中的交互式上下文化工具让你能够结合机器学习、强大的规则引擎和域专业知识,在 CDF 数据模型中相互映射不同来源系统中的资源。
例如,你可以从静态 PDF 源文件构建交互式工程图,并匹配实体以从浏览器设置、自动执行和验证所有上下文化管道,而无需撰写任何代码。
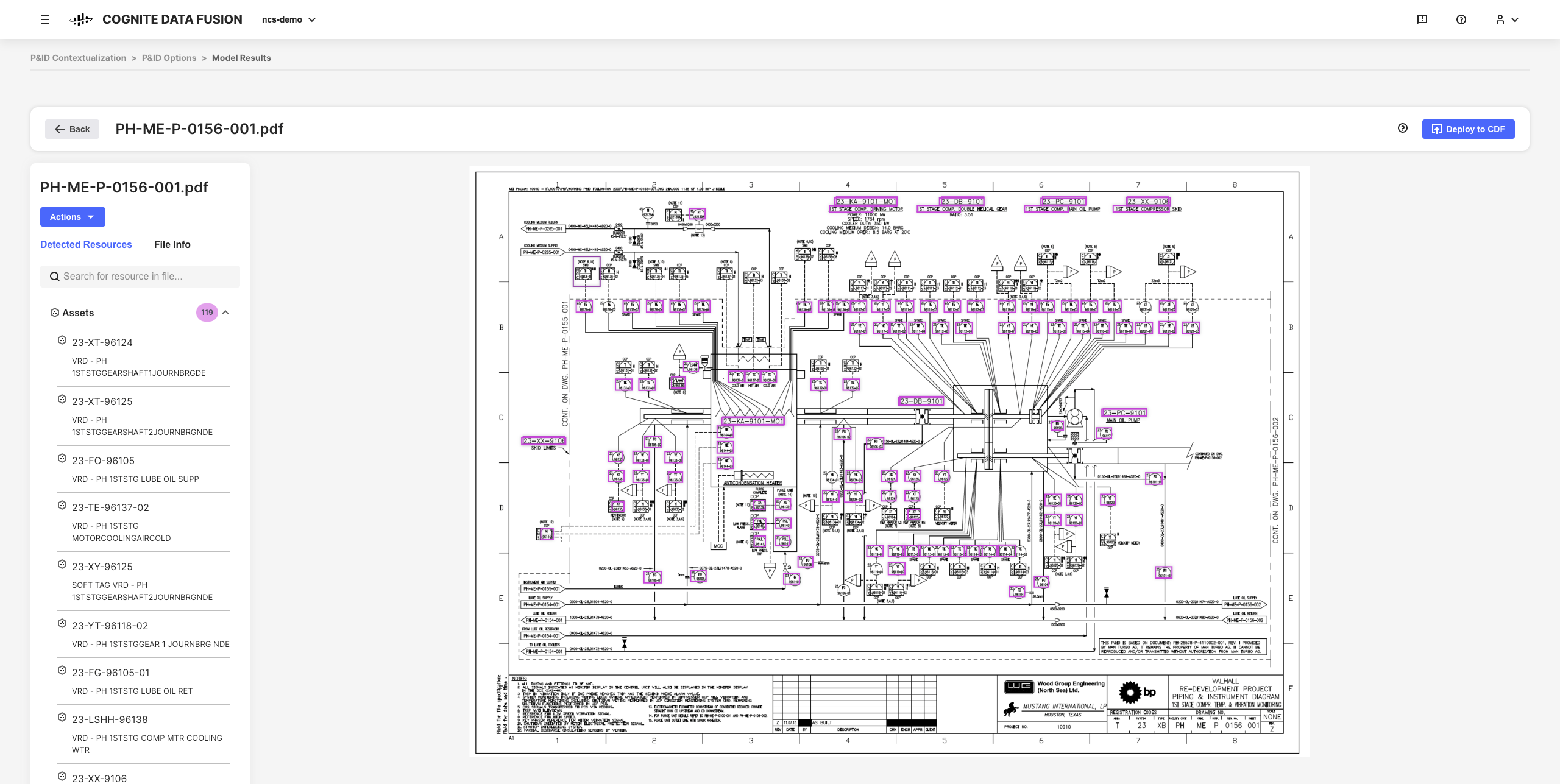
所生成的优化数据和推断洞察是在整个组织扩展 CDF 实施和解决方案的基础,让你能够更深入地了解自己的数据。