데이터 통합
Cognite Data Fusion(CDF)에서 데이터를 분석하고 컨텍스트화하려면 기존 데이터 인프라와 CDF 데이터 모델 간에 효율적인 데이터 통합 파이프라인을 설정해야 합니다.
CDF에서 데이터 통합 파이프라인은 일반적으로 데이터 추출, 변환 및 컨텍스트화 단계를 포함합니다. 이 단원에서는 이러한 각 단계에 대해 자세히 살펴보겠습니다.
데이터를 CDF 데이터 모델에 통합하기 위해 PostgreSQL 및 OPC-UA 같은 표준 프로토콜 및 인터페이스뿐만 아니라 Cognite 또는 타사 추출기 및 변환 도구를 사용할 수 있습니다. 이러한 도구는 데이터 작업에 필수적이며, 데이터 통합 파이프라인에는 가능한 한 유지 관리하기 쉽도록 모듈식 설계를 사용하는 것이 좋습니다.
데이터 추출
추출 도구는 원본 시스템에 연결하고 데이터를 원래 형식으로 스테이징 영역에 푸시합니다. 데이터 추출기는 다양한 모드에서 작동합니다. 데이터를 스트리밍하거나 배치의 데이터를 스테이징 영역으로 추출할 수 있습니다. 또한 데이터 변환을 거의 또는 전혀 수행하지 않고 직접 CDF 데이터 모델로 데이터를 추출할 수 있습니다.
데이터 원본에 대한 읽기 액세스 권한이 있으면 시스템 통합을 설정하여 데이터를 CDF 스테이징 영역(RAW)으로 스트리밍할 수 있으며, 이 스테이징 영역에서 데이터를 정규화하고 보강할 수 있습니다. Cognite는 PostgreSQL 및 OPC-UA 같은 표준 프로토콜 및 인터페이스를 지원하므로 기존 ETL 도구 및 데이터 웨어하우스 솔루션과의 데이터 통합이 용이합니다.
또한 특정 산업 시스템용으로 맞춤 제작된 추출기와 SQL 호환 데이터베이스의 보다 전통적인 테이블 형식 데이터를 위한 표준 상용 제품 ETL 도구도 제공합니다.
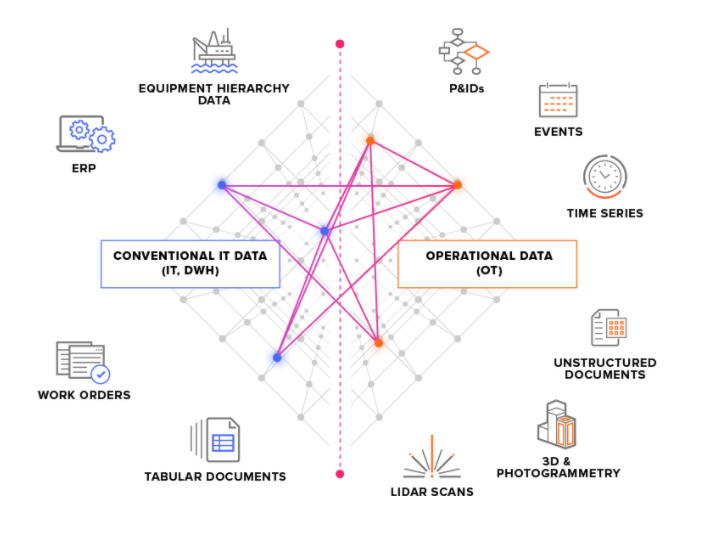
원본 시스템은 두 가지 기본 유형으로 나뉩니다.
-
OT 원본 시스템 - 시계열 데이터를 포함하는 산업용 제어 시스템을 예로 들 수 있습니다. CDF로 OT 데이터를 가져오는 작업에는 시간이 중요할 수 있으며(몇 초 안에 완료해야 함), 데이터는 연속적으로 추출해야 하는 경우가 많습니다.
-
IT 원본 시스템 - ERP 시스템, 파일 서버, 데이터베이스, 엔지니어링 시스템(3D CAD 모델) 등을 예로 들 수 있습니다. IT 데이터는 일반적으로 OT 데이터에 비해 자주 변경되지 않으므로(몇 분 또는 몇 시간) 배치 작업으로 추출할 수 있습니다.
스테이징 영역 대안
데이터는 추출기에서 CDF 수집 API로 전달됩니다. 여기서부터 모든 데이터는 클라우드에 존재합니다. 첫 번째 목적지는 CDF 스테이징 영역(RAW)이며, 여기에서 테이블 형식의 데이터가 원래 형식으로 저장됩니다. 이 방식을 통해 추출기의 논리를 최소화하고 클라우드에서 데이터에 대한 변환을 실행 및 재실행할 수 있습니다.
이미 클라우드에 스트리밍되어 저장된 데이터가 있는 경우(예: 데이터 웨어하우스에 저장된 데이터), 해당 데이터를 CDF 스테이징 영역으로 통합하고 Cognite's 도구를 사용하여 데이터를 변환할 수 있습니다. 또는 클라우드에서 데이터를 변환하고 CDF 스테이징 영역을 건너뛰어 데이터를 직접 CDF 데이터 모델에 통합할 수도 있습니다.
데이터 변환
변환 단계에서는 스테이징 영역의 데이터를 CDF 데이터 모델에 맞게 변형하여 이동합니다. 일반적으로 이 단계에 대부분의 데이터 처리 로직이 포함됩니다.
데이터 변환에는 일반적으로 다음과 같은 단계가 하나 이상 포함됩니다.
CDF데이터 모델에 맞게 데이터의 형태를 재구성합니다. 예를 들어,CDF RAW에서 데이터 개체를 읽고 이를 이벤트의 형태로 변경합니다.- 추가 정보로 데이터를 보강합니다. 예를 들어, 다른 원본의 데이터를 추가합니다.
- 데이터를 컬렉션 내의 다른 데이터 개체와 일치시킵니다.
- 데이터의 품질을 분석합니다. 예를 들어, 데이터 개체에 필요한 모든 정보가 있는지 확인합니다.
데이터 변환을 위해 기존의 추출, 변환, 로드(ETL) 도구를 사용하는 것을 권장하지만, 가벼운 변환 작업을 위한 대안으로 CDF Transformation 도구도 제공합니다. CDF Transformations 변환을 사용하면 브라우저 내에서 Spark SQL 쿼리를 사용하여 데이터를 변환할 수 있습니다.
사용하는 도구에 관계없이, CDF's RAW 저장소 또는 동등한 스테이징 시스템의 데이터를 Cognite 데이터 모델로 변환하며, 이 단계에서 심층 분석 및 실시간 인사이트를 위해 추가적인 관계로 데이터를 보강할 수 있습니다.
데이터 향상
데이터 통합 파이프라인에서 가장 중요한 요소는 컨텍스트화입니다. 이 프로세스에서는 머신 러닝, 강력한 규칙 엔진 및 전문 분야 지식을 결합하여 다양한 원본 시스템의 리소스를 CDF 데이터 모델에서 서로에게 매핑시킵니다.
컨텍스트화의 첫 번째 부분은 각 고유 엔터티가 원본 시스템에서 서로 다른 ID를 갖는 경우에도 CDF에서 동일한 식별자를 공유하도록 보장하는 것입니다. 이 단계는 주로 수신 데이터의 형태를 변경하고 일치시킨 후 컬렉션의 기존 리소스와 비교하는 변환 단계에서 수행됩니다.
컨텍스트화 프로세스의 다음 단계는 실제 세계에서의 관계와 동일한 방식으로 엔터티를 서로 연관시키는 것입니다. 예를 들어, 3D 모델 내의 개체는 자산에 매핑할 수 있는 ID를 가질 수 있으며, 계측 모니터링 시스템에서 얻은 시계열은 동일한 자산에 할당할 수 있는 다른 ID를 가질 수 있습니다.
CDF의 대화형 컨텍스트화 도구를 사용하면 머신 러닝, 강력한 규칙 엔진 및 전문 분야 지식을 결합하여 다양한 원본 시스템의 리소스를 CDF 데이터 모델에서 서로에게 매핑시킬 수 있습니다.
예를 들어, 정적 PDF 원본 파일에서 대화형 엔지니어링 다이어그램을 작성하고 엔터티를 일치시켜 어떠한 코드도 작성할 필요 없이 브라우저에서 모든 컨텍스트화 파이프라인을 설정하고, 자동화하며, 유효성을 검사할 수 있습니다.
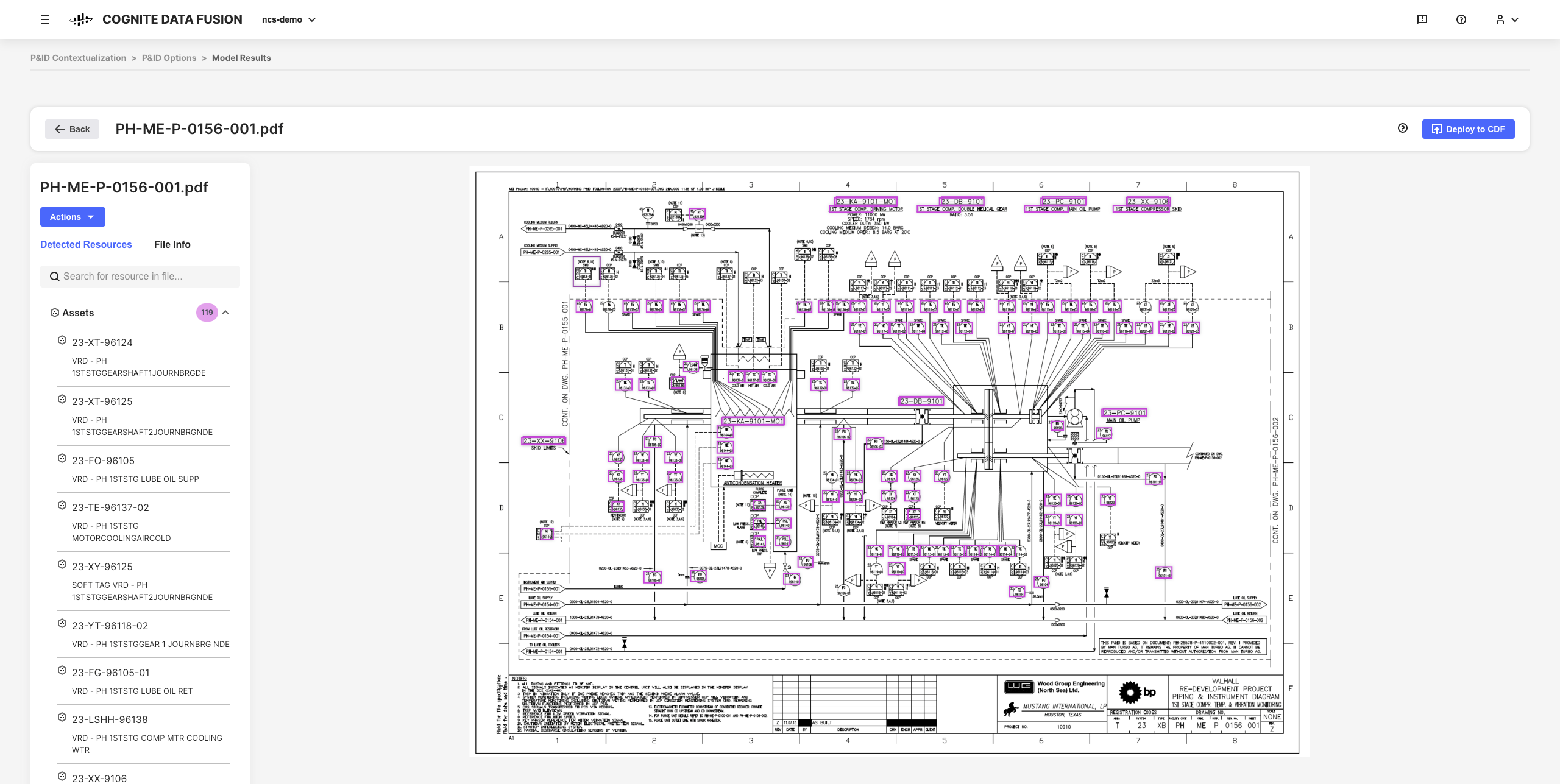
구체화된 결과 데이터와 유추된 인사이트는 데이터에 대한 보다 심층적인 이해를 발전시킬 때 조직 전체에서 CDF 구현 및 솔루션을 확장할 수 있는 기반이 됩니다.