Integrere data
Du må etablere effektive dataintegreringsledninger mellom den eksisterende datainfrastrukturen og CDF-datamodellen for å kunne analysere og kontekstualisere dataene i Cognite Data Fusion (CDF).
I CDF omfatter en dataintegreringskanal vanligvis trinn for å trekke ut, endre og kontekstualisere data. I denne enheten skal vi ta en nærmere titt på hvert av disse trinnene.
Når du skal integrere data i CDF-datamodellen, kan du bruke standardprotokoller og -grensesnitt som PostgreSQL og OPC-UA i tillegg til Cognite eller tredjepartsverktøy for uttrekking og endring. Verktøyene er viktige for dataoperasjonene dine, og vi anbefaler at du bruker en modulær design for dataintegreringskanalene for å gjøre dem så enkle å vedlikeholde som mulig.
Trekk ut data
Uttrekkingsverktøyene kobles til kildesystemene og sender data i originalformatet til landingssonen. Datauttrekkere fungerer i ulike moduser. De kan strømme data eller trekke ut data i batcher til landingssonen. De kan også trekke ut data direkte til CDF-datamodellen med liten eller ingen dataendring.
Med lesetilgang til datakildene kan du konfigurere systemintegreringen til å strømme data til CDF landingssonen (RAW), der dataene kan normaliseres og berikes. Vi støtter standardprotokoller og grensesnitt som PostgreSQL og OPC-UA for å tilrettelegge for dataintegrering med de eksisterende ETL-verktøyene dine og datalagerløsningene.
Vi har også uttrekkere som er skreddersydd for bransjespesifikke systemer og standard ETL-verktøy for mer tradisjonelle tabulære data i SQL-kompatible databaser.
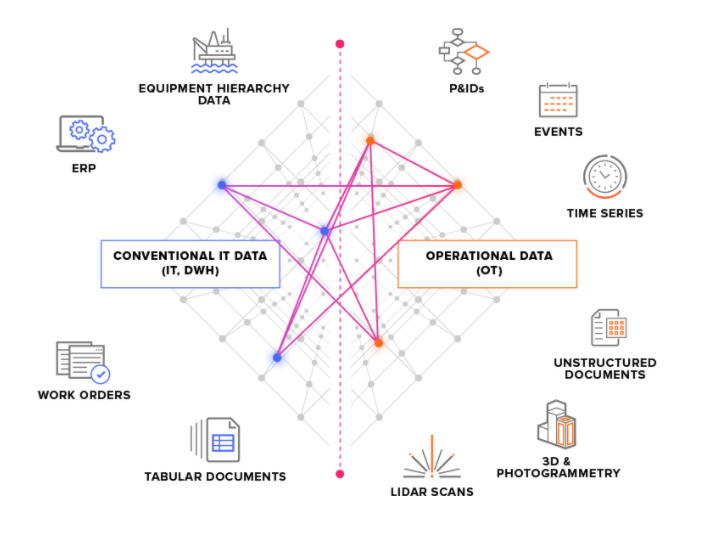
Vi deler inn kildesystemer i to hovedtyper:
-
OT-kildesystemer – for eksempel industrielle kontrollsystemer med tidsseriedata. Det å hente OT-data inn i CDF kan være tidskritisk (noen sekunder), og dataene må ofte trekkes ut kontinuerlig.
-
IT-kildesystemer – for eksempel ERP-systemer, filservere, databaser og tekniske systemer (3D-CAD-modeller). IT-data endrer seg normalt ikke like ofte (minutter eller timer) som OT-data og kan ofte trekkes ut batchvis.
Alternativer for landingssonen
Dataflyter fra uttrekkerne til CDF-inntaks-API-et. Herfra er alt i skyen. Det første stoppet er CDF-landingssonen (RAW), der tabulære data er lagret i originalformatet. Denne tilnærmingen gjør at du kan redusere logikken i uttrekkerne og kjøre transformasjoner på data i skyen om og om igjen.
Hvis du allerede har dataene strømmet til og lagret i skyen, for eksempel i et datalager, kan du integrere dataene i CDF-landingssonen derfra og endre dataene med Cognite's-verktøy. Alternativt kan du endre dataene i skyen og forbigå CDF-landingssonen for å integrere dataene direkte i CDF-datamodellen.
Endre data
Endringstrinnet former og flytter dataene fra oppsettingsområdet til CDF-datamodellen. Dette er det trinnet der mesteparten av databehandlingslogikken vanligvis ligger.
Dataendring omfatter vanligvis ett eller flere av disse trinnene:
- Omforming av dataene, slik at de skal passe til
CDF-datamodellen. Du kan for eksempel lese et dataobjekt fraCDF RAWog forme det til en hendelse. - Beriking av dataene med mer informasjon. For eksempel kan du legge til data fra andre kilder.
- Matching av dataene med andre dataobjekter i samlingen.
- Analyse av kvaliteten på dataene. Du kan for eksempel kontrollere om all nødvendig informasjon er til stede i dataobjektet.
Vi anbefaler at du bruker de eksisterende ETL-verktøyene (ETL = Extract, Transform, Load, dvs. trekke ut, transformere, laste inn) til å endre dataene, men vi tilbyr også verktøyet CDF Transformation som et alternativ ved lette transformeringsjobber. Med CDF Transformations kan du bruke Spark SQL-spørringer til å endre data fra nettleseren.
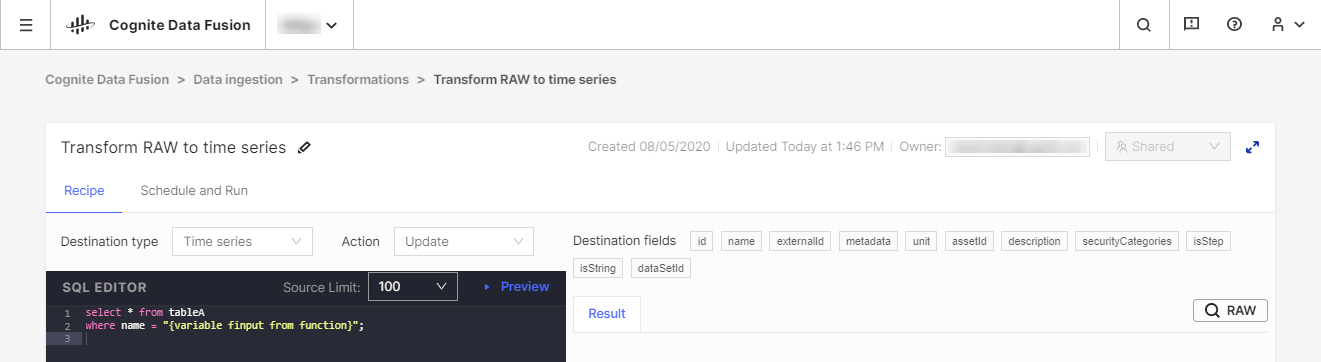
Uavhengig av hvilket verktøy du bruker, endrer du data fra CDF's RAW-lagringsplassen eller en tilsvarende landingssone inn i Cognite-datamodellen, der du kan berike dataene ytterligere med flere relasjoner for å få dyptgående analyser og innsikt i sanntid.
Forbedre data
En svært viktig del av dataintegreringskanalene dine er kontekstualisering. Denne prosessen kombinerer maskinlæring, en kraftig regelmotor og kunnskap om området for å kunne tilordne ressurser fra ulike kildesystemer til hverandre i CDF-datamodellen.
Den første delen av kontekstualisering går ut på å sikre at hver unik enhet deler den samme identifikatoren i CDF, selv om den har ulike ID-er i kildesystemene. Dette trinnet utføres for det meste under endringen, når du former og tilpasser innkommende data og sammenligner dem med eksisterende ressurser i samlingen.
Det neste trinnet i kontekstualiseringsprosessen er å forbinde enheter med hverandre på den samme måten de henger sammen på i den virkelige verden. Et objekt i en 3D-modell kan for eksempel ha en ID som du kan tilordne til en tagg, og en tidsserie fra et instrumentovervåkingssystem kan ha en annen ID som du kan tilordne til den samme taggen.
De interaktive kontekstualiseringsverktøyene i CDF lar deg kombinere maskinlæring, en kraftig regelmotor og ekspertise på området for å kunne tilordne ressurser fra ulike kildesystemer til hverandre i CDF-datamodellen.
Du kan for eksempel bygge interaktive tekniske diagrammer fra statiske PDF-kildefiler og matche enheter som skal konfigureres, automatisere og validere alle kontekstualiseringskanaler fra nettleseren uten at du trenger å skrive noe kode.
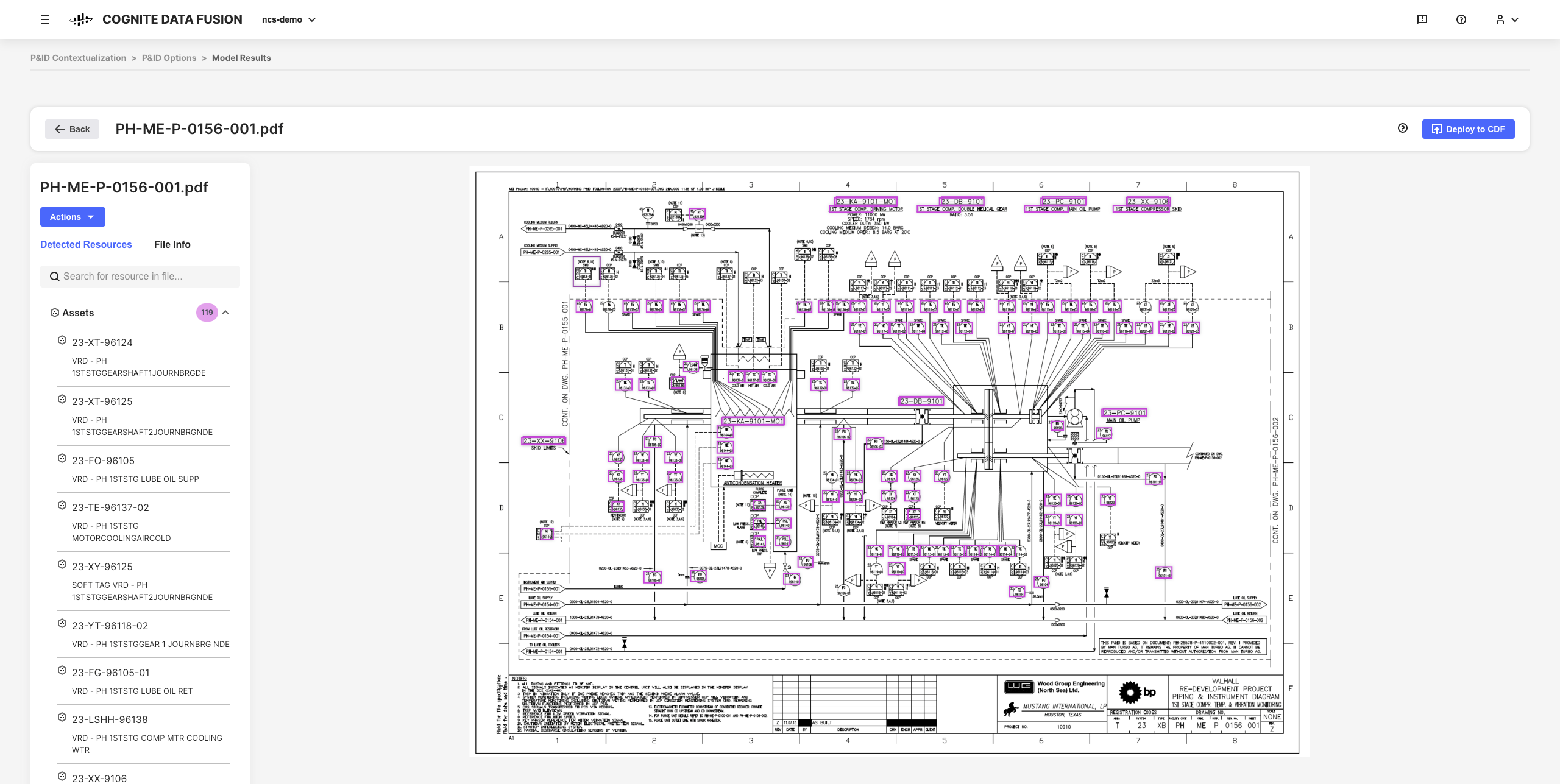
De resulterende raffinerte dataene og de antydede innsiktene er grunnlaget for å skalere CDF-implementeringen og -løsningene i hele bedriften etter hvert som du utvikler en dypere forståelse av dataene.