Before you start
- Assign access capabilities for the extractor to write data to the respective CDF destination resources.
- If the database you’re connecting to requires the extractor to use ODBC, download and install the ODBC drivers for your database.
- Review the server requirements for the extractor.
- Create a configuration file according to the configuration settings. The file must be in YAML format.
Connect to a database
Native
The extractor has native support for some databases and doesn’t require any additional drivers.ODBC
To connect via ODBC, you must install an ODBC driver for your database system on the machine where you’re running the extractor. Here are links to ODBC drivers for some source systems:- MS SQLServer
- MySQL
- Oracle
ODBC connection strings
ODBC uses connection strings to reference databases. The connection strings contain information about which ODBC driver to use, where to find the database, sign-in credentials, etc.Set up a Data Source Name (DSN)
We recommend setting up a DSN for the database if you’re running the extractor against an ODBC source on Windows. The Windows DSN system handles password storage instead of keeping it in the configuration file or as an environment variable. In addition, the connection strings will be less complex.1
Open ODBC Data Sources tool
Open the ODBC Data Sources tool on the machine you’re running the extractor from.
2
Add ODBC driver
Select Add and the ODBC driver you want to use. In this example, we’re configuring a PostgreSQL database.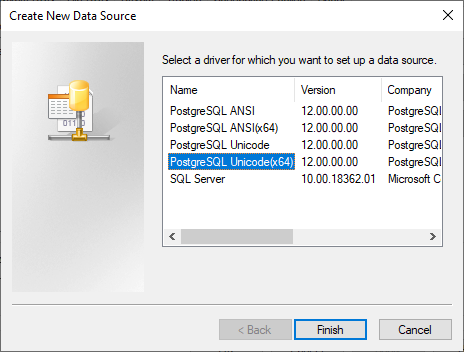
3
Complete the setup
Select Finish.
4
Enter connection information
Enter the connection information and the database name.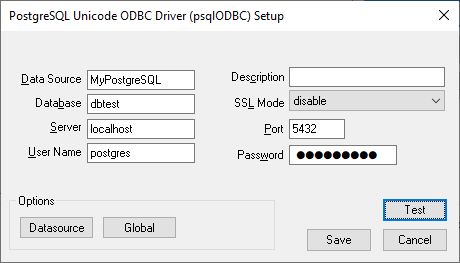
The configuration dialog may differ depending on which database type you are configuring a DSN for.
5
Test and save
Select Test to verify that the information is correct, then Save.
6
Use the connection string
Use the simplified connection string in your configuration file:
Run the extractor
- Windows executable
- Windows service
- Docker
1
Download the executable
Download the
dbextractor-standalone-{VERSION}-win32.exe file via the download links available from the Cognite DB extractor section on the Extract data page in CDF.2
Save the file
Save the file in a folder.
3
Run the extractor
Open a command line window and run the file with a configuration file as an argument.In this example, the configuration file is named
config.yml and saved in the same folder as the executable file:Load data incrementally
If the database table has a column containing an incremental field, you can set up the extractor to only process new or updated rows since the last extraction. An incremental field is a field that increases for new entries, such as time stamps for the latest update or insertions if the rows never change, or a numerical index. To load data incrementally for a query:1
Configure state store
Include the
state-store parameter in the extractor section of the configuration.2
Set incremental parameters
Include the
incremental-field and initial-start parameters in the query configuration.3
Update SQL query
Update the SQL query with a
WHERE statement using {incremental-field} and {start-at}. For example:LIMIT statement. Be aware that this demands a well-defined paging strategy. Consider this example: