CDF-datamodellen og ressurstyper
Denne enheten ser på Cognite Data Fusion (CDF)-datamodellen og de ulike ressurstypene du kan bruke til å modellere og organisere dataene.
En datamodell er en abstrakt modell som organiserer dataelementer og standardiserer hvordan de henger sammen med hverandre og attributtene til enheter i den virkelige verden. CDF-datamodellen samler inn industrielle data gjennom ressurstyper som gjør at du kan definere dataelementene, angi attributtene deres og modellere relasjonene mellom dem. De ulike ressurstypene brukes både til å lagre og organisere data.
Ressurstyper for å lagre data
De fleste ressurstypene i CDF brukes til å lagre ulike typer data. La oss ta en nærmere titt på dem:
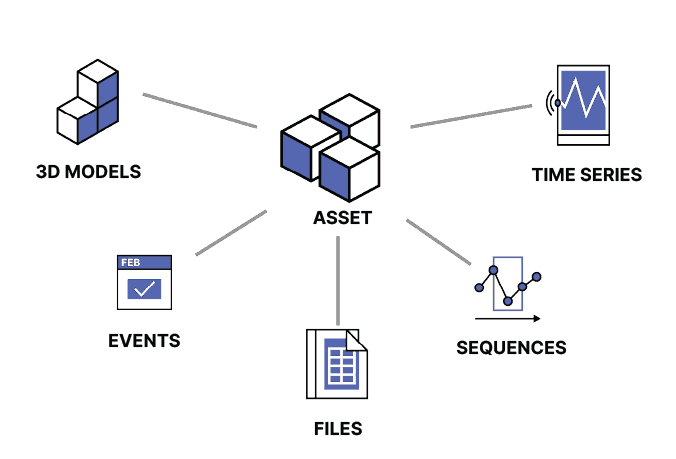
Assets (tagger)
Vi starter med ressurstypen tagger. Den lagrer digitale representasjoner av objekter eller grupper med objekter fra den fysiske verdenen.
Tagger kobler sammen tilknyttede data fra ulike kilder og er det sentrale når det gjelder å identifisere alle de relevante dataene for et objekt. Alle andre ressurstyper, for eksempel tidsserier, hendelser og filer, bør være koblet til minst én tagg, og hver tagg kan kobles til mange ressurser og ressurstyper.
Tagger organiseres vanligvis i hierarkier. Eksempel: En vannpumpe-tagg kan være en del av en delsystem-tagg i en anleggs-tagg.
Time series (tidsserie)
Ressurstypen time series lagrer en serie med datapunkter i kronologisk rekkefølge. Eksempler på en tidsserie er temperaturen til en vannpumpe-tagg, månedlig nedbør for en lokasjon og det daglige gjennomsnittlige antallet produksjonsdefekter.
Events (hendelser)
Ressurstypen events lagrer informasjon om ting som skjer i løpet av en tidsperiode. Hendelser har et starttidspunkt og et sluttidspunkt og kan være knyttet til flere tagger. En hendelse kan for eksempel beskrive to timer med vedlikehold på en vannpumpe og tilhørende rør eller en fremtidig tidsperiode der pumpen er planlagt å skulle inspiseres.
Files (filer)
Ressurstypen files lagrer dokumenter som inneholder informasjon knyttet til én eller flere tagger. En fil kan for eksempel inneholde et rør- og instrumenteringsdiagram (P&ID) som viser hvordan flere tagger henger sammen.
3D models (3D-modeller)
Ressurstypen 3D models lagrer filer som gir visuelle og geometriske data og kontekst for tagger. Vi kan for eksempel koble en pumpetagg til en 3D-modell av anleggsetasjen den befinner seg i.
Det å se taggdata gjengitt i 3D er flott med tanke på å oppdage og finne dataene du er interessert i. Ved å gjengi analyseresultater i 3D kan du bedre forstå data, for eksempel ved å utheve alt utstyr som har hatt problemer det siste året.
Sequences (sekvenser)
Ressurstypen sequences lagrer serier med rader indeksert etter radnummer. Hver rad inneholder én eller flere kolonner med enten strengdata eller numeriske data. Eksempler på sekvenser er ytelseskurver og ulike typer logger, for eksempel dybdelogger innen boring.
Ressurstyper for å organisere data
En mindre gruppe ressurstyper lar deg organisere og definere relasjonen mellom ressurstypene for lagring:
Relationships (relasjoner)
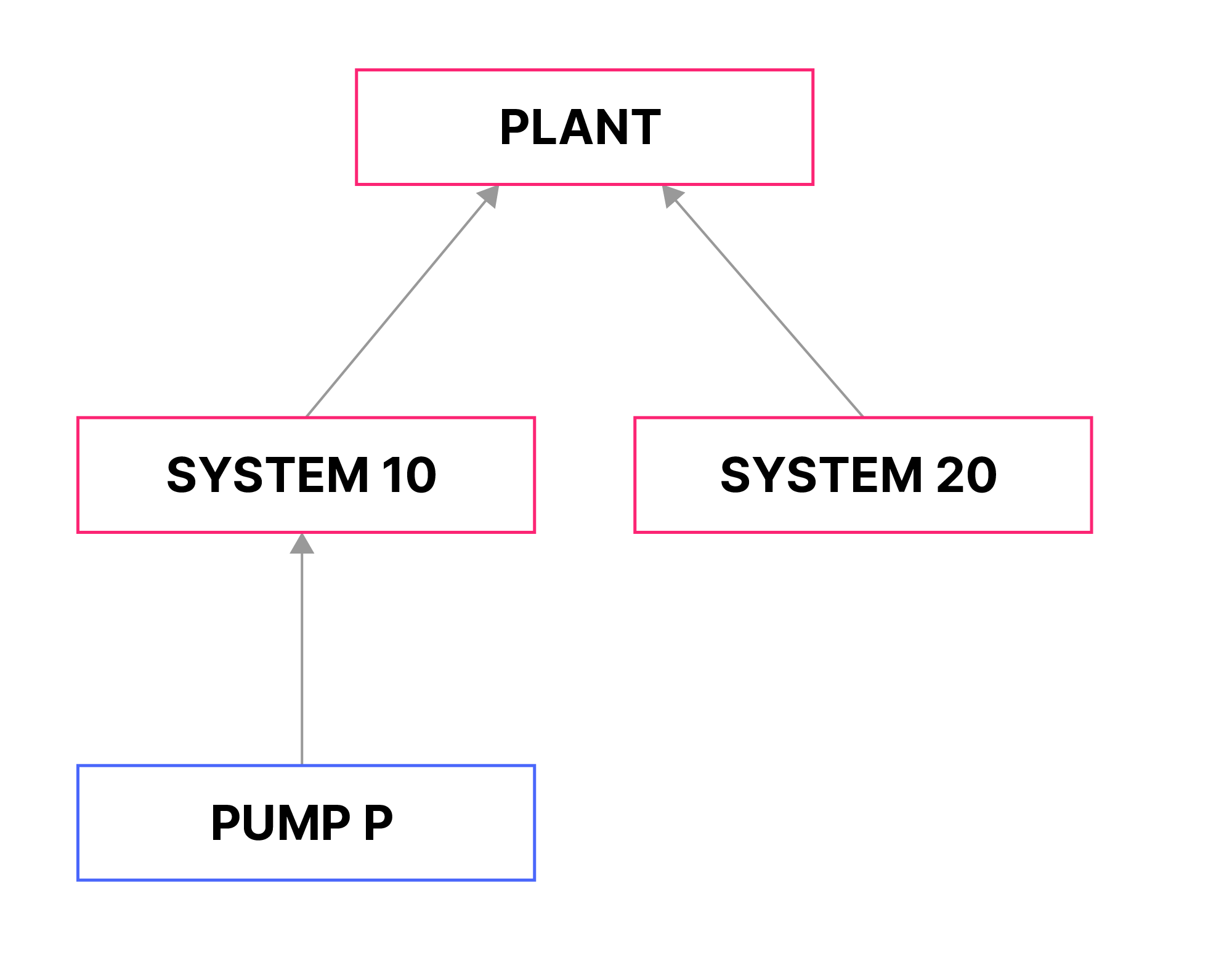
Ressurstypen Relationships representerer forbindelser mellom ressursobjekter i CDF. Hver relasjon er mellom et kilde- og et målobjekt og kan være tidsbegrenset med et start- og sluttidspunkt.
En måte å bruke relasjoner på er å organisere tagger i andre strukturer i tillegg til den vanlige hierarkiske tagg-strukturen.
Du kan for eksempel velge å organisere tagger etter fysisk lokasjon eller bygge en grafstruktur som gjør at du kan navigere i tagger ved å etterligne de fysiske forbindelsene deres gjennom ledninger eller rør.
Labels (etiketter)
Med labels kan du opprette et forhåndsdefinert sett med administrerte vilkår som du kan bruke til å kommentere og gruppere tagger. Du kan organisere etikettene på en måte som gir mening i bransjen, og bruke etikettene for å gjøre det lettere å finne det du leter etter.
Du kan for eksempel opprette en etikett kalt pumpe, bruke den på alle tagg-ressurser som representerer pumper, og deretter filtrere tagger slik at du bare ser pumper.
Data sets (datasett)
Et data set er en beholder for dataobjekter og har metadata med informasjon om dataene det inneholder. Datasett grupperer og sporer data etter datakilden. Du kan for eksempel bruke datasettets metadata til å dokumentere hvem som er ansvarlig for dataene, laste opp dokumentasjonsfiler, beskrive dataenes opprinnelse, og så videre.
Datasett er en viktig del av det å designe og implementere retningslinjer for datastyring, og dette er temaet for den neste enheten.