Bästa metoder och felsökning
Få ut det mesta av Cognite Power BI connector med dessa bästa metoder och felsökningstips.
Bästa metoder för prestanda
Prestandan för Cognite Power BI connector beror på resurstyperna Cognite Data Fusion (CDF) du har åtkomst till. Till exempel tar läsning av 1M datapunkter cirka 2:30 till 3:00 minuter (6K datapunkter per sekund). Varje fullständig förfrågan tar i genomsnitt 120 ms, och anslutningen lägger till i genomsnitt 20 ms till CDF-förfrågningar.
Följ dessa allmänna bästa metoder för att se till att du får bästa och mest pålitliga prestanda:
- Använd inte
OR-uttryck eller expanderande tabeller. - Använd flera frågor när det är möjligt.
- Använd inkrementell uppdatering.
- Partitionera datamängder om möjligt.
- Behåll bara de data du behöver. Ta bort onödiga kolumner och data.
- Spara historiska data i en separat rapport om du inte behöver data dagligen. Uppdatera den historiska datarapporten när du behöver data.
- Minska antalet beräkningar/operationer i frontend, och försök att göra så mycket som möjligt i datamodelleringen.
Skriv presterande frågor
OData-tjänsten accepterar flera samtidiga förfrågningar och behandlar förfrågningarna parallellt. Power BI skickar också flera frågor samtidigt när det är möjligt.
Därför är det bättre att komponera och använda flera frågor istället för en enda komplex fråga med till exempel OR-uttryck eller expander. En enda komplex fråga måste itereras sekventiellt med den tillagda fördröjningen för varje begäran.
Försök istället att ladda ner data med flera frågor:
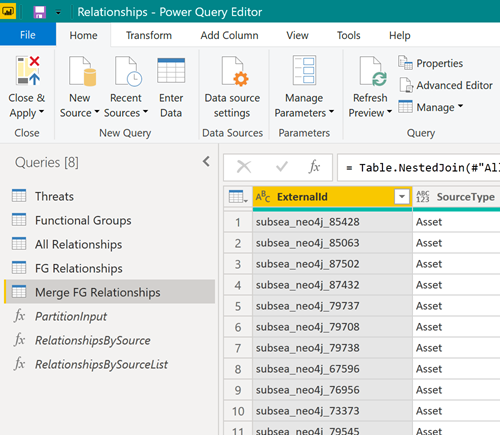
Slå sedan ihop de resulterande tabellerna i Power BI-datamodellen för att arbeta med tabellerna som om de vore en enda tabell:
Använd inkrementell uppdatering
Inkrementell uppdatering möjliggör stora datamängder i Power BI med följande fördelar:
- Endast data som har ändrats behöver uppdateras.
- Du behöver inte upprätthålla långvariga anslutningar till källsystem.
- Mindre data att uppdatera minskar den totala förbrukningen av minne och andra resurser.
Läs mer om inkrementell uppdatering.
Partitionera stora datamängder
Om du behöver ladda ner stora datamängder, försök att partitionera datamängden och ha en separat fråga för att läsa varje partition. Power BI behandlar flera frågor samtidigt, och partitionering av datamängden kan förbättra prestandan avsevärt.
Om du till exempel läser datapunkter från de senaste två åren kan du prova att dela upp frågan i två frågor som var och en läser ett års data. Slå sedan samman (konkatenera) tabellerna i Power BI.
Rensa cachen
Power BI cachar tjänstemanifestet som beskriver schemat för OData-tjänsten. När anslutningen eller OData-tjänsten uppgraderas kan du behöva rensa Power BI-cachen för att tvinga Power BI att läsa tjänstemanifestet igen.
Rensa cachen så här:
-
I
Power BI Desktopväljer duFil > Alternativ och inställningar > Alternativ > Dataladdning. -
Under Alternativ för hantering av datacache väljer du Rensa Cache.
Egenskapsnamn i metadata och CDF RAW
Egenskapsnycklar för metadata och CDF mellanlagringsområde (RAW) måste vara giltiga identifierare och får bara innehålla bokstäver, siffror eller understreck. OData-tjänsten skriver om alla andra tecken till ett understreck. För bästa och mest förutsägbara resultat, se till att intagen data följer denna namnkonvention för egenskapsnycklar: ^[a-zA-Z][_a-za-z0-9]\*[a-zA-Z0-9]\$.
Felsökning
Hitta information som hjälper dig att felsöka problem med CDF som datakälla i Power BI.
Frågor tar för lång tid
Ett CDF-projekt kan innehålla hundratals miljoner rader med data, och att ladda dem alla i Power BI är inte genomförbart. Om din fråga tar timmar att köra försöker du med största sannolikhet ladda för mycket data.
Använd informationen i artikeln filtrering för att begränsa mängden data som laddas i Power BI.
Får inte alla resultat
Om du får färre resultat än förväntat kanske du använder en filterfunktion som CDF inte stöder, som t.ex. startswith i kolumnen Namn för TimeSeries.
För mer information, se Filtring som stöds för CDF-resurser.
Det går inte att hämta minimala värden från CDF RAW
Om du använder data från CDF-mellanlagringsområdet, CDF RAW i Power BI, kan du uppleva problem med att hämta små tal i exponentiell notation.
CDF RAW har inget schema, men OData-biblioteken i Power BI försöker välja rätt format för data. För närvarande väljer Power BI fel avkodare för små tal i exponentiell notation, och du kan få ett fel som liknar detta:
DataSource,Error: OData: Cannot convert the literal '2.89999206870561 to the expected type 'Edm.Decimal',
För att lösa problemet, mata in värdena i CDF RAW som strängar istället för siffror och konvertera tillbaka strängarna till siffror i Power BI, till exempel med hjälp av Decimal.From Power Query M-funktionen. Du kommer inte att förlora precision, och eftersom de flesta JSON-avkodare accepterar strängar för siffror, kommer klienter som förväntar sig siffror fortfarande att fungera.