모범 사례 및 문제 해결
다음과 같은 모범 사례 및 문제 해결 팁을 참조하여 Cognite Power BI connector를 최대한 활용하십시오.
성능 모범 사례
Cognite Power BI connector의 성능은 액세스하는 Cognite Data Fusion(CDF) 리소스 유형에 따라 달라집니다. 예를 들어, 100만 개 데이터 요소를 읽는 데 약 2분 30초에서 3분이 걸립니다(초당 6,000개 데이터 요소). 전체 요청 하나에 평균 120밀리초가 소요되며, 커넥터는 CDF 요청마다 평균적으로 20밀리초를 추가합니다.
다음과 같은 일반적인 모범 사례에 따르면 최고의 성능을 안정적으로 얻을 수 있습니다.
OR식이나 확장 테이블을 사용하지 마십시오.- 가능한 경우 여러 개의 쿼리를 사용하십시오.
- 증분 새로 고침을 사용하십시오.
- 가능한 경우 데이터 집합을 분할하십시오.
- 필요한 데이터만 유지하십시오. 불필요한 열과 데이터를 제거하십시오.
- 일상적으로 필요한 것이 아니라면 기록 데이터를 별도의 보고서에 유지하십시오. 데이터가 필요한 경우 기록 데이터 보고서를 새로 고치십시오.
- 프론트 엔드에서 계산/연산의 수를 줄이고 데이터 모델링에서 가능한 많은 작업을 수행하십시오.
고성능 쿼리 작성
OData 서비스는 여러 동시 요청을 수락하고 병렬로 요청을 처리합니다. Power BI도 가능한 경우 여러 쿼리를 동시에 전송합니다.
따라서 OR 식이나 확장 등을 포함하는 복잡한 쿼리 하나를 사용하는 것보다 여러 쿼리를 구성하고 사용하는 것이 더 좋습니다. 복잡한 단일 쿼리는 순차적으로 반복되어야 하며, 각 요청에서 추가적인 라운드트립 지연 시간이 발생합니다.
대신 다음과 같이 여러 쿼리를 사용하여 데이터를 다운로드해 보십시오.
그런 다음 Power BI 데이터 모델에서 결과 테이블을 조인하여 마치 단일 테이블인 것처럼 작업할 수 있습니다.
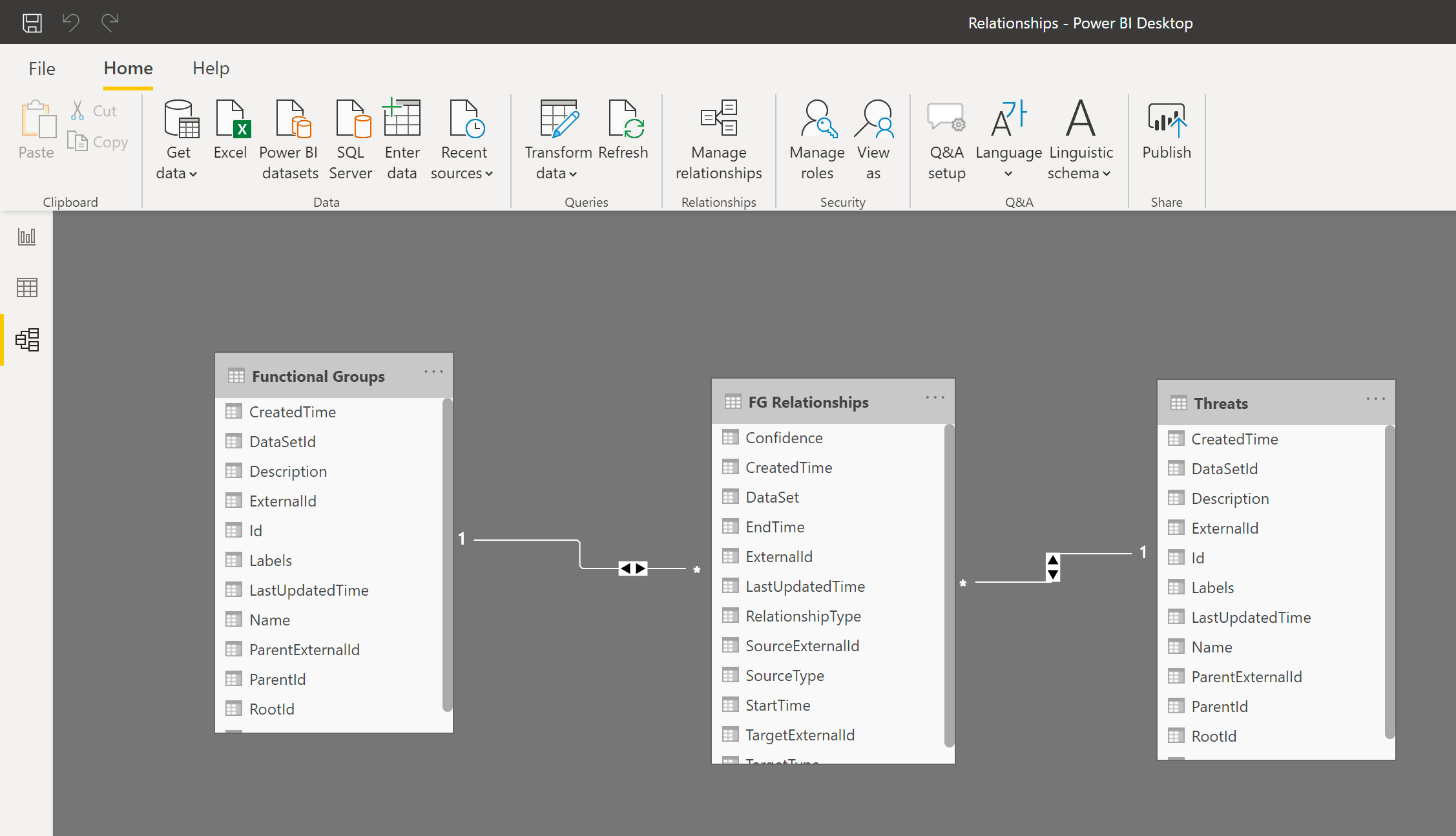
증분 새로 고침 사용
증분 새로 고침을 사용하면 Power BI에서 다음과 같은 이점을 가진 대규모 데이터 집합을 실현할 수 있습니다.
- 변경된 데이터만 새로 고치면 됩니다.
- 원본 시스템에 대한 연결을 오랜 시간 유지할 필요가 없습니다.
- 새로 고쳐야 할 데이터가 적어지므로 메모리 및 기타 리소스의 전체적인 사용량이 감소합니다.
증분 새로 고침에 대해 자세히 알아보십시오.
대규모 데이터 집합 분할
대규모 데이터 집합을 다운로드해야 하는 경우 데이터 집합을 파티션으로 분할하고 각 파티션을 읽는 별도의 쿼리를 작성하십시오. Power BI는 여러 쿼리를 동시에 처리하며, 데이터 집합을 파티션으로 분할하면 성능이 크게 향상될 수 있습니다.
예를 들어, 지난 2년간의 데이터 요소를 읽는다면 모든 데이터를 읽는 쿼리 하나보다 1년치의 데이터를 읽는 두 개의 쿼리로 분할하는 것이 좋습니다. 그런 다음 Power BI에서 테이블을 병합(연결)하십시오.
캐시 지우기
Power BI는 OData 서비스의 스키마를 설명하는 서비스 매니페스트를 캐시에 저장합니다. 커넥터나 OData 서비스가 업그레이드되는 경우 Power BI 캐시를 지워 Power BI가 서비스 매니페스트를 다시 읽도록 해야 할 수 있습니다.
캐시를 지우려면 다음과 같이 하십시오.
-
Power BI Desktop에서 파일 > 옵션 및 설정 > 옵션 > 데이터 로드를 선택합니다. -
데이터 캐시 관리 옵션에서 캐시 지우기를 선택합니다.
메타데이터 및 CDF RAW의 속성 명명 규칙
메타데이터 및 CDF 스테이징 영역(RAW)의 속성 키는 유효한 식별자여야 하며 문자, 숫자 또는 밑줄만 포함할 수 있습니다. OData 서비스는 다른 문자를 모두 밑줄로 바꿉니다. 최상의 예측 가능한 결과를 얻으려면 수집된 데이터가 속성 키에 대해 ^[a-zA-Z][_a-za-z0-9]\*[a-zA-Z0-9]\$ 명명 규칙을 따르는지 확인하십시오.
문제 해결
Power BI에서 CDF를 데이터 원본으로 사용할 때 발생하는 문제를 해결하는 데 도움이 되는 정보를 찾아보십시오.
너무 오랜 시간이 걸리는 쿼리
CDF 프로젝트에는 수억 개의 데이터 행이 포함될 수 있으며, 이를 모두 Power BI로 로드하는 것은 현실적이지 않습니다. 쿼리를 실행하는 데 몇 시간이 걸린다면 대개 너무 많은 데이터를 로드하려고 시도한 것입니다.
필터링 문서에 제공된 정보를 참조하여 Power BI로 로드되는 데이터 양을 제한하십시오.
일부 결과를 가져오지 못함
결과의 수가 예상보다 적다면 CDF에서 지원하지 않는 필터 함수를 사용하는 것일 수 있습니다. 예를 들어, TimeSeries에 대한 Name 열에 startswith를 사용하고 있을 수 있습니다.
자세한 내용은 CDF 리소스에 대해 지원되는 필터링을 참조하십시오.
CDF RAW에서 최소값을 검색할 수 없음
Power BI에서 CDF 스테이징 영역인 CDF RAW의 데이터를 사용하는 경우 지수 표기법 형식의 작은 숫자를 검색할 때 문제가 발생할 수 있습니다.
CDF RAW에는 스키마가 없지만 Power BI의 OData 라이브러리는 이 데이터에 대해 올바른 형식을 선택하려고 시도합니다. 현재 Power BI는 지수 표기법 형식의 작은 숫자에 ��대해 잘못된 디코더를 선택하며, 다음과 유사한 오류가 발생할 수 있습니다.
DataSource,Error: OData: Cannot convert the literal '2.89999206870561 to the expected type 'Edm.Decimal',
이 문제를 해결하려면 CDF RAW로 값을 가져올 때 숫자 대신 문자열로 가져온 다음, Power BI에서 문자열을 다시 숫자로 변환하십시오. 예를 들어, Decimal.From Power Query M 함수를 사용합니다. 이렇게 하면 정밀도가 손실되지 않으며, 대부분의 JSON 디코더가 숫자를 나타내는 문자열을 수용하므로 숫자를 예상하는 클라이언트도 작동할 것입니다.