最佳实践和故障排除
遵循这些最佳实践和故障排除提示,以最有效地利用 Cognite Power BI connector。
性能最佳实践
Cognite Power BI connector 的性能取决于你访问的 Cognite Data Fusion (CDF) 资源类型。例如,读取 1M 数据点大约需要 2.5 到 3 分钟(每分钟 6K 数据点)。每个完整请求平均需要 120 毫秒,连接器会向 CDF 请求增加平均 20 毫秒。
遵循这些常规最佳实践,以确保获得最佳且最可靠的性能:
- 切勿使用
OR表达式或展开表格。 - 尽量使用多个查询。
- 使用增量刷新。
- 如有可能,分割数据集�。
- 仅保留需要的数据。删除不需要的列和数据。
- 如果不需要每天获得数据,则将历史数据保留在单独的报告中。需要数据时刷新历史数据报告。
- 减少前端的计算/操作数量,并尝试在数据建模中尽可能多地执行操作。
编写高性能查询
OData 服务可接受多个并发请求并平行处理这些请求。如果可能,Power BI 还会同时发出多个查询。
因此,最好编写和使用多个查询,而不是使用单个复杂查询,例如 OR 表达式或扩展。单个复杂查询必须按顺序迭代,每个请求都会增加往返延迟。
因此,请尽量使用多个查询下载数据:
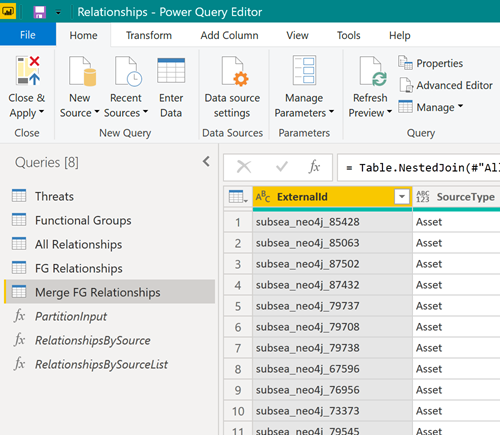
接下来,在 Power BI 数据模型中合并生成的表格,以便像处理单个表格一样处理这些表格:
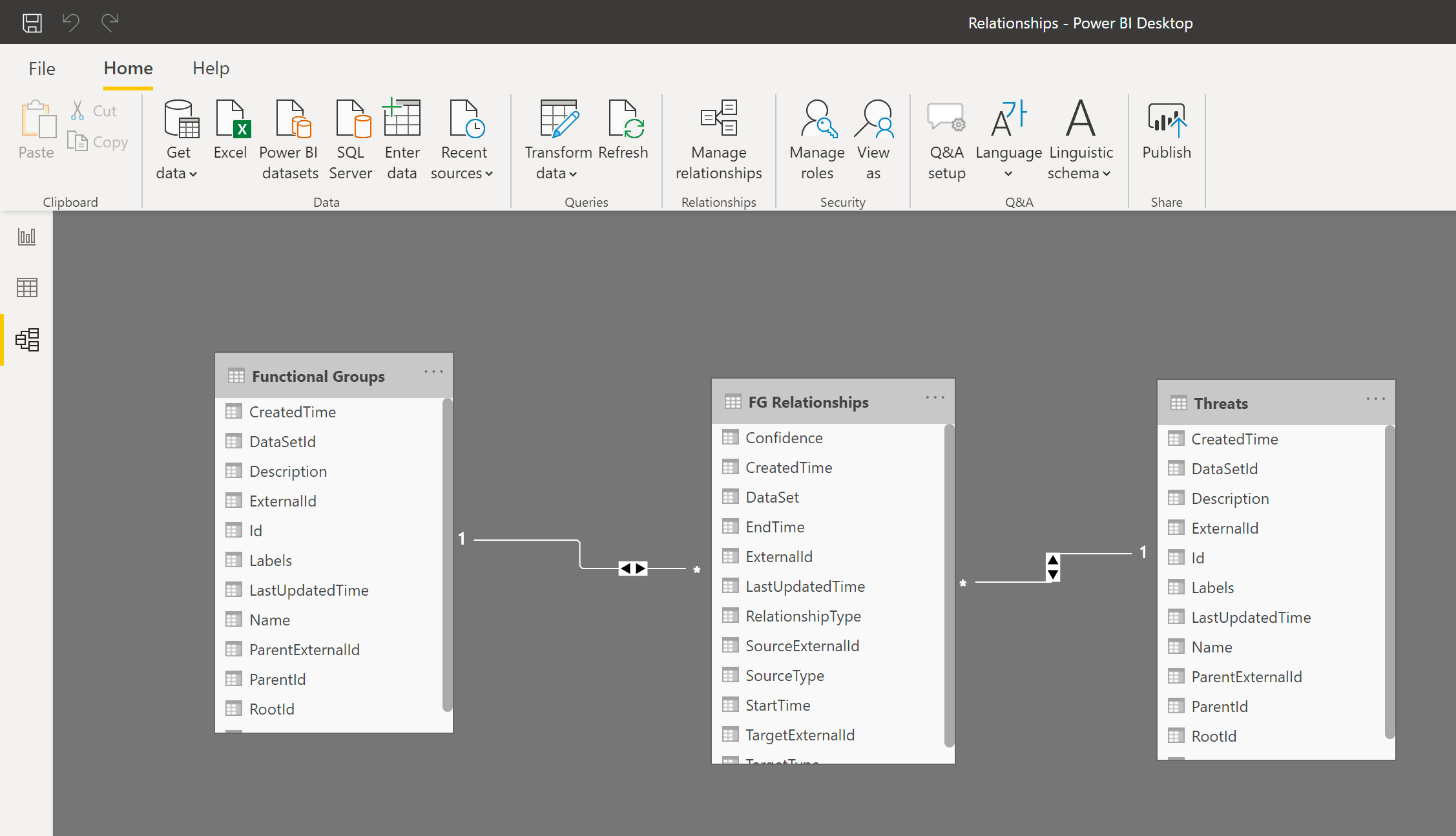
使用增量刷新
增量刷新能够在 Power BI 中赋予大型数据集以下优点:
- 仅刷新需要更改的数据。
- 不需要与来源系统保持长时间运行的连接。
- 刷新较少的数据可以减少内存和其他资源的消耗量。
了解更多关于增量刷新的信息。
分割大型数据集
如果需要下载大型数据库,请尝试分割数据集,并使用单独的查询读取分割后的每个部分。Power BI 可同时处理多个查询,分割数据集能够显著提高性能。
例如,如果你要读取过去两年的数据点,请尝试将查询拆分成两个查询,各读取一年的数据。然后,在 Power BI 中合并(连接)表格。
清除缓存
Power BI 可缓存描述 OData 服务架构的服务清单。升级连接器或 OData 服务时,可能需要清除 Power BI 缓存以强制 Power BI 重新读取服务清单。
清除缓存:
-
在
Power BI Desktop中,选择文件 > 选项和设置 > 选项 > 数据加载。 -
在数据缓存管理选项下,选择清除缓存。
元数据和 CDF RAW 中的属性命名
元数据和 CDF 数据准备区 (RAW) 的属性键必须是有效标识符,并且只能包含字母、数字或下划线。OData 服务会将任何其他字符重写为下划线。为了获得最佳且最可预测的结果,请确保引入的数据�遵循此属性键命名约定:^[a-zA-Z][_a-za-z0-9]\*[a-zA-Z0-9]\$。
故障排除
查找信息以帮助排查在 Power BI 中使用 CDF 作为数据源时出现的问题。
查询耗时过长
CDF 项目可能包含数亿行的数据,因此将它们全部加载到 Power BI 中不可行。如果执行查询需要几个小时,则极有可能是因为正在尝试加载太多数据。
使用筛选文章中的信息限制加载到 Power BI 中的数据量。
未获得全部结果
如果获得的结果少于预期,可能是因为你使用了 CDF 不支持的筛选器功能,例如在时间序列的名称列中使用 startswith。
如需了解更多信息,请参阅 CDF 资源支持的筛选。
无法从 CDF RAW 检索最小值
如果在 Power BI 中使用来自 CDF 数据准备区 CDF RAW 的数据,检索采用指数表示法的小数字时可能会遇到问题。
CDF RAW 没有架构,但��是 Power BI 中的 OData 库尝试为数据选择正确的格式。目前,Power BI 为指数表示法的小数字选择了错误的解码器,你可能遇到与以下相似的错误:
DataSource,Error: OData: Cannot convert the literal '2.89999206870561 to the expected type 'Edm.Decimal',
要解决此问题,请将值作为字符串而非数字引入 CDF RAW,然后在 Power BI 中将字符串转换回数字,例如使用 Decimal.From Power Query M-函数。这样不会损失精度,而且由于大部分 JSON 解码器都接受数字字符串,因此需要数字的客户端仍可正常工作。