- For coordinated pipelines, prefer Data workflows over time-based schedules.
- You can also transform data using the Cognite API, and the Cognite Python SDK.
- Use the Cognite Toolkit when you want to manage transformations as code. The Toolkit lets you define transformations, schedules, and notifications in YAML (with optional SQL files) and deploy them through CI/CD.
Before you start
Make sure you’ve completed these steps to register an app for the transformation in your identity provider (IdP) and to set up the necessary folders and capabilities to run or schedule transformations.- The data you want to transform must conform to the structure defined by the data model.
- Capabilities limit which resource types your transformation can read and write when it runs. They do not determine which options appear under Action while you configure the transformation.
Step 1: Create a transformation
1
Navigate to Transformations
Navigate to Data fusion > Integrate > Transformations.
2
Create new transformation
Select Create, and enter a unique name and a unique external ID.
3
Optional. Associate to data set
Associate the transformation to an existing data set to restrict who can access the transformation.
4
Continue to next step
Select Next.
5
Select target data model
Select the target data model that contains the target resource type.
- CDF resource types - select this model to ingest data into an asset hierarchy.
- If you’re ingesting data into the Assets resource type, make sure a parent asset already exists in CDF.
- If you’re ingesting data into Sequence rows, specify the external ID for the sequence you want to write to. This defines the target schema.
- CDF staging area - select this model to ingest data into the CDF staging area. You must specify the target database and table.
- User defined data models - select this model to ingest data in a user defined data model. Enter the target space you want to write data to and the version of the data model. CDF sets the default space from the data model. You can ingest data into a type or a relationship.
6
Select action type
The available action types depend on the target data model and target resource type you selected in the previous step. Some resource types support the full set of action types while others support only a subset.
- Select Keep existing values to not update existing data. This is the default setting.
- Select Clear existing values to set existing values to null, for example, when a piece of equipment is removed for maintenance. Use this option to disassociate the asset from its parent in the asset hierarchy.
To delete existing rows in a CDF staging table, you must use the Transformations API.
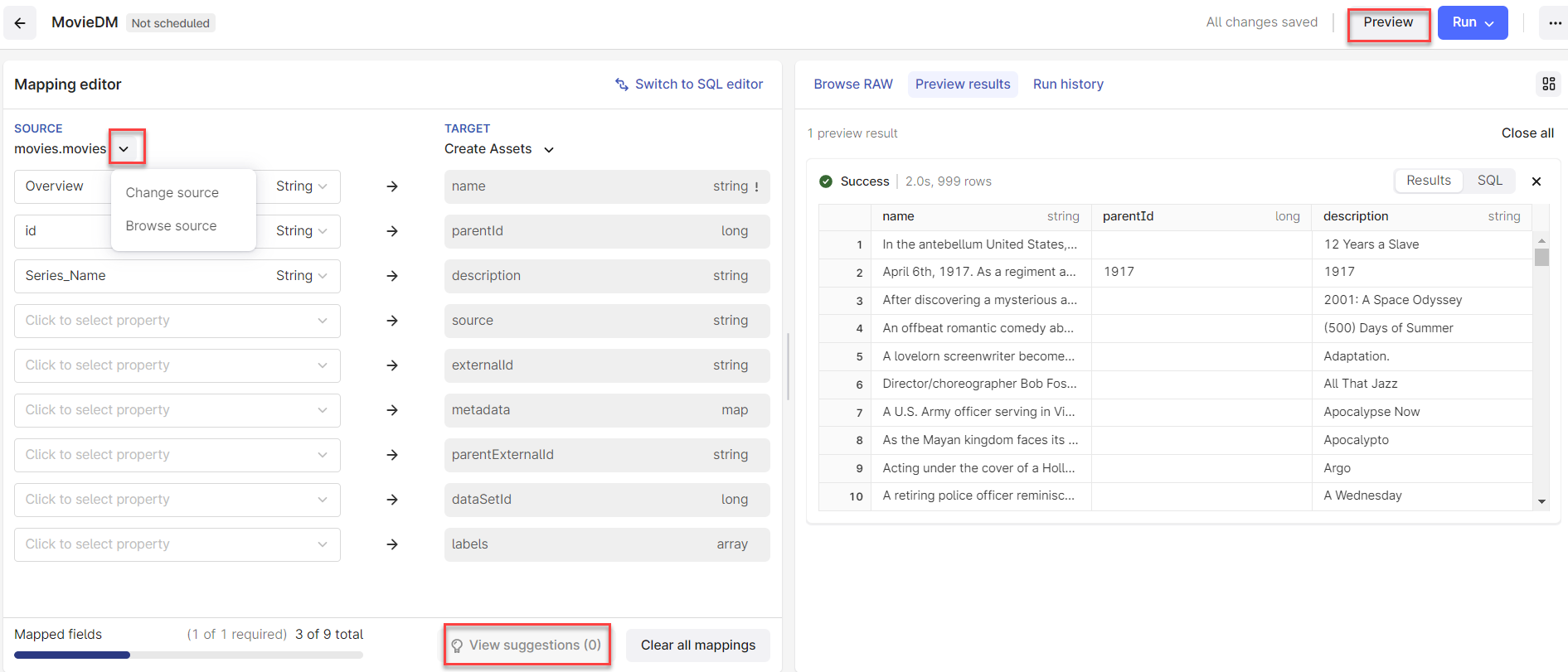
Step 2: Map source and target data
In the editor pane, you can create transformations with the mapping editor or enter Spark SQL queries. Typically, you would use the mapping editor to copy data from source to target resource types and use SQL queries to perform more complex transformations.Using the mapping editor
1
Map source to target fields
Select the source table and map source fields to the target fields.
2
Preview the transformation
Select Preview to verify that the transformation produces the expected output.
Using Spark SQL
Select Switch to SQL editor to create a transformation in Spark SQL. The SQL editor offers built-in code completion with built-in Spark SQL functions and Cognite custom SQL functions. See SQL syntax and functions for reference.
Step 3: Transform data
Select Run to start a transformation, or follow the steps in schedule transformations to run your transformation at regular intervals. Select Run with client credentials and specify Client ID and the Client secret for the app you registered for the transformation in Microsoft Entra ID. CDF automatically refills the remaining fields. You can also select Run as current user when you want to run one-time transformations, for instance, to create the root node in an asset hierarchy, create a new RAW table from other RAW tables, or add data manually. We recommend using Run with client credentials. You can select the Advanced authentication method to specify separate credentials for reading and writing data, for instance, if you want to transform data between different projects. If you don’t know what values to enter in these fields, contact your internal help desk or the CDF admin for help.Step 4: Schedule transformations
1
Open schedule settings
Select Run > Set schedule.
2
Enter credentials
The first time you schedule a transformation, you must enter your Client ID and the Client secret.
3
Configure schedule
Specify when and how often you want the transformation should run. Select a predefined schedule or specify a cron expression.For example, 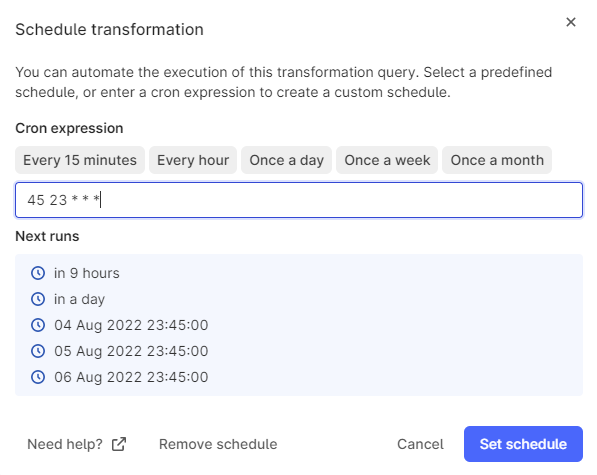
45 23 * * * will run the transformation at 23:45 (11:45 PM) every day.4
Activate the schedule
Select Set schedule to activate the schedule. CDF sets the transformation to read-only to prevent unintentional changes to future scheduled jobs.
5
Review run metrics
Check the run history to evaluate performance. For data model write jobs, the No operations (no-op) metric shows write operations skipped because identical data already exists in CDF. A high no-op count suggests opportunities to implement incremental data loads.For incremental processing, RAW usage, and load management guidance, see Operations and performance.
When using the Transformations API, you can create up to 1000 schedules or notification subscriptions per request. Job listings return up to 1000 items per request (default 100).
Step 5: Monitor transformations
To monitor the transformation process and solve any issues before they reach the data consumer, you can subscribe to email notifications if a transformation fails.If runs fail or behave unexpectedly, see Troubleshooting transformations.
1
Open monitoring settings
Navigate to the More options (…) and select Monitor.
2
Configure email notifications
Enter email addresses that will receive notifications if this transformation fails.