Modeling an asset hierarchy
This article describes the asset hierarchy template in the Cognite Data Fusion (CDF) templates repository. An asset hierarchy describes connections between larger assets and the smaller components inside them. The tools and information in the in the tools are provided as-is, without any support or warranties,
We recommend that you read this article to become familiar with the asset hierarchy template before you try it in your Cognite Data Fusion (CDF) project.
The tools and templates in the Cognite Data Fusion (CDF) templates repository are community-supported with contributions from Cognite engineers.
The template first creates a generic asset data model and then a use-case-specific data model and demonstrates how to:
- Store data and data models in containers.
- Populate data models with transformation jobs.
- Use the existing system containers and views.
- Consume the data models with GraphQL and SDKs.
The template models an asset hierarchy with two levels, lift stations and pumps, where the pumps are children of a lift station:
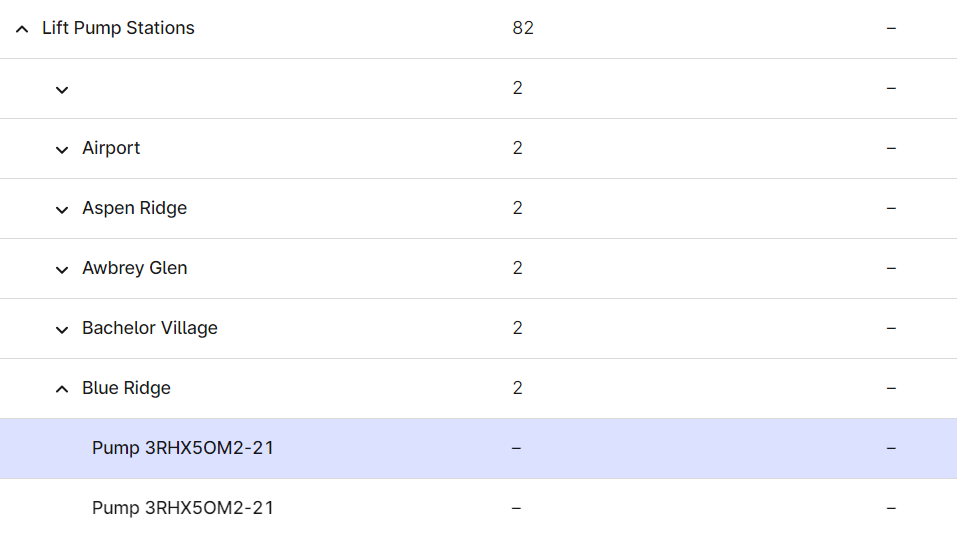
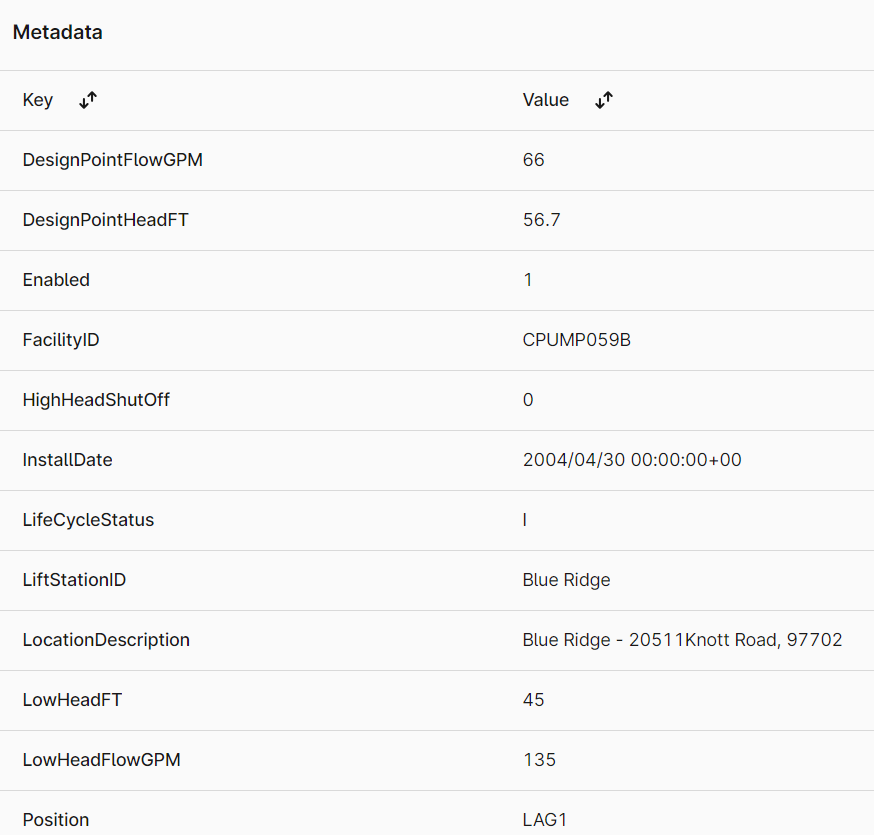
Each of the pumps has properties in a metadata key-value store:
The data models
This section describes the views, the solution data model for the template. The containers, the physical storage, are covered in the next section.
Generic asset model
The template starts with a generic asset model. The data model has one view, Asset:

The data model is generic, and you can use it for both lift stations and pumps. However, you can't define properties specifically for pumps since the properties would also apply to lift stations. Therefore, the model is useful for creating an overview of all assets, but you need additional data models tailored to specific use cases.
Use-case-specific data model
The use-case-specific data model has two views, LiftStation and Pump. There's a one-to-many edge from LiftStation to Pump and a direct relation from Pump to LiftStation.
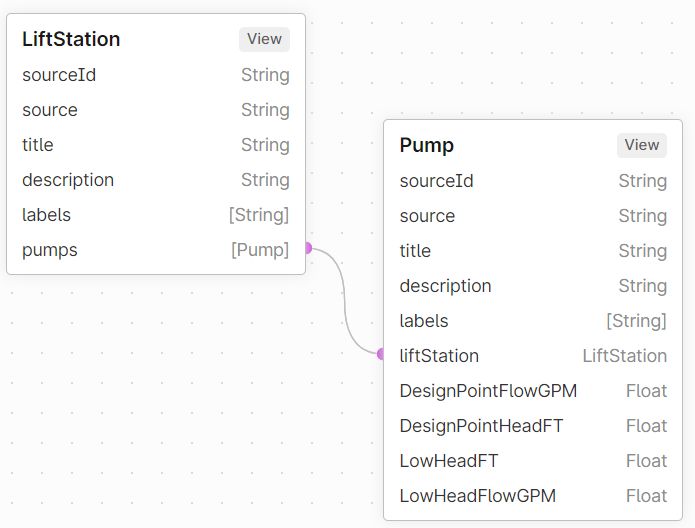
The data model fits the use case, and you can query it in a language close to the domain, for example, "get all pumps in lift station 1."
Note that while the data model is well suited for building a solution in the domain of pump lift stations, you likely can't use it for other use cases.
Implementing the physical schema backing your data model
When you create data models, you need to consider containers and how to store data. Containers handle the physical storage of data models and are similar to SQL tables.
While views are reasonably easy to create, modify, and delete, containers are more permanent, and any changes often require costly migration of data. Carefully consider which properties to include in each container, keeping the following questions in mind:
-
How can you avoid duplication of data? Duplication can lead to inconsistencies and increased storage costs.
-
What queries do you expect? Consider which indexes you need in the containers. Indexes speed up queries, but increase the cost of writing.
-
What structure do you want to enforce on the data? Defining required properties or requiring a matching row to exist in another container lets you protect data quality by rejecting write operations of incomplete data.
When you design containers, Cognite recommends using system containers and views as much as possible. They're pre-defined and designed to fit common industrial use cases and are available in the cdf_core space.
Implementing the pump lift station use case
Generic asset model
The generic asset model is similar to the Asset system view in the cdf_core space. The only difference is the added metadata property.
We don't recommend using a generic metadata property of type JSON. See how the Asset system view can be extended in the example.
To store the metadata property, the template uses a new container, AssetMetadata, in the myModelSpace space. One potential issue is that the container could be used to store any information in the metadata property. To make sure that it's only used for assets, we've added a constraint to the Asset container in the cdf_core system space.
The template defines the container specification in a YAML file and writes it to CDF using the container API.
externalId: AssetMetadata
name: Asset
space: myModelSpace
usedFor: node
properties:
metadata:
autoIncrement: false
defaultValue: null
description: Custom, application specific metadata. String key -> String value.
name: metadata
nullable: true
type:
list: false
type: json
constraints:
requiredAsset:
constraintType: requires
require:
type: container
space: cdf_core
externalId: Asset
Next, the template creates an Asset view for the generic asset model. Because the view is in the myModelSpace space, it won't collide with the system Asset view.
Instead of creating one property in the new view for each property in the Asset, Describable, and Sourceable containers, the template uses the Asset view from the cdf_core space, which already has all the properties. Only the metadata property needs to be added:
externalId: Asset
name: Asset
space: myModelSpace
version: '1'
implements:
- type: view
space: cdf_core
externalId: Asset
version: v1
properties:
metadata:
container:
externalId: Asset
space: myModelSpace
type: container
containerPropertyIdentifier: metadata
name: metadata
The final step is to create the data model with a single view:
externalId: myGenericAssetModel
name: myGenericAssetModel
space: myModelSpace
version: 1
views:
- externalId: Asset
space: myModelSpace
type: view
version: 1
Use-case-specific data model
For the use-case-specific data model, the template uses two views, LiftStation and Pump. The LiftStation view doesn't have any properties that aren't already in the system Asset view. (The pumps property is a one-to-many edge that isn't stored in containers.) Therefore, we don't need a container for the lift station.
The pump view has four new properties, DesignPointFlowGPM, DesignPointHeadFt, LowHeadFT, and LowHeadFlowGPM, that you need to create a container for. In the template, we've added a constraint to the Asset container to disallow pumps without an asset.
This is the specification for the Pump container:
externalId: Pump
name: Pump
space: myModelSpace
usedFor: node
properties:
DesignPointFlowGPM:
autoIncrement: false
defaultValue: null
description: The flow the pump was designed for, specified in gallons per minute.
name: DesignPointFlowGPM
nullable: true
type:
list: false
type: float64
DesignPointHeadFT:
autoIncrement: false
defaultValue: null
description: The flow head pump was designed for, specified in feet.
name: DesignPointHeadFT
nullable: true
type:
list: false
type: float64
LowHeadFT:
autoIncrement: false
defaultValue: null
description: The low head of the pump, specified in feet.
name: LowHeadFT
nullable: true
type:
list: false
type: float64
LowHeadFlowGPM:
autoIncrement: false
defaultValue: null
description: The low head flow of the pump, specified in gallons per minute.
name: DesignPointHeadFT
nullable: true
type:
list: false
type: float64
constraints:
requiredAsset:
constraintType: requires
require:
type: container
space: cdf_core
externalId: Asset
When creating the LiftStation view, the template doesn't use the Asset view from the system space because we don't need the root and parent properties. Instead, the template uses the Describable and Sourceable views from the system space.
You also need to add the pumps property as a one-to-many edge from LiftStation to Pump. You don't want to get all assets from the Asset container, only the lift stations. To achieve this, the template uses a filter on the externalId of the asset. During data population, the template ensures that all lift stations have an externalId that starts with lift_station.
This is the specification for the LiftStation view:
externalId: LiftStation
name: LiftStation
space: myModelSpace
version: 1
implements:
- type: view
space: cdf_core
externalId: Sourceable
version: v1
- type: view
space: cdf_core
externalId: Describable
version: v1
properties:
pumps:
type:
space: myModelSpace
externalId: LiftStation.pumps
source:
space: myModelSpace
externalId: Pump
version: 1
type: view
direction: outwards
name: pumps
filter:
prefix:
property:
- node
- externalId
value: lift_station
Next, the template creates the Pump view. As with the LiftStation view, we can't use the Asset view from the system space. Instead, the template uses the Describable and Sourceable views from the system space.
The template uses the parent property from the Asset container in the system space. Instead of calling it parent, the template adds a direct relation property linking to the parent property and names it liftStation.
To distinguish the pumps from other assets, the template adds a filter on the externalId of the asset. During data population, the template ensures that all pumps have an externalId that starts with pump.
externalId: Pump
name: Pump
space: myModelSpace
version: 1
implements:
- type: view
space: cdf_core
externalId: Sourceable
version: v1
- type: view
space: cdf_core
externalId: Describable
version: v1
properties:
liftStation:
container:
externalId: Asset
space: cdf_core
type: container
containerPropertyIdentifier: parent
name: liftStation
source:
external_id: LiftStation
space: myModelSpace
version: 1
DesignPointFlowGPM:
container:
externalId: Pump
space: myModelSpace
type: container
containerPropertyIdentifier: DesignPointFlowGPM
name: DesignPointFlowGPM
DesignPointHeadFT:
container:
externalId: Pump
space: myModelSpace
type: container
containerPropertyIdentifier: DesignPointHeadFT
name: DesignPointHeadFT
LowHeadFT:
container:
externalId: Pump
space: myModelSpace
type: container
containerPropertyIdentifier: LowHeadFT
name: LowHeadFT
LowHeadFlowGPM:
container:
externalId: Pump
space: myModelSpace
type: container
containerPropertyIdentifier: LowHeadFlowGPM
name: LowHeadFlowGPM
filter:
prefix:
property:
- node
- externalId
value: pump
Having defined the two views, we can create the data model:
externalId: LiftStationPump
name: LiftStationPump
space: myModelSpace
version: 1
views:
- externalId: Pump
space: myModelSpace
type: view
version: 1
- externalId: LiftStation
space: myModelSpace
type: view
version: 1
Populating data models
Data models and the data they contain often require different access patterns. Data models are typically read-only, while the data is read-write. In the template, we use a new space, myDataSpace, to store the data for the data models.
Generic asset model
To populate the generic asset model, the template uses a transformation to move data into the Asset view created earlier from the CDF asset hierarchy, lift_pump_stations:root, or the CDF staging area, RAW.
Under the Asset view, the template uses the Asset system container from the cdf_core system space. The container has a constraint on the parent property and requires that the parent exists to allow write operations. Consequently, the data must be populated in one step per level in the asset hierarchy, first the lift stations, and then the pumps. To separate lift stations from pumps, the externalId must start with lift_station for the lift stations and with pump for the pumps.
This is the specification for the SQL transformation:
-- Pump stations
select
concat('lift_station:', cast(`externalId` as STRING)) as externalId,
null as parent,
null as root,
cast(`name` as STRING) as title,
cast(`source` as STRING) as source,
cast(`description` as STRING) as description,
cast(`labels` as ARRAY < STRING >) as labels,
to_json(`metadata`) as metadata
from
cdf_assetSubtree('lift_pump_stations:root')
where
isnotnull(`externalId`) and isnotnull(`parentExternalId`) and not startswith(name, 'Pump')
UNION ALL
-- Pumps
select
concat('pump:', cast(`externalId` as STRING)) as externalId,
node_reference('myDataSpace', `parentExternalId`) as parent,
null as root,
cast(`name` as STRING) as title,
cast(`source` as STRING) as source,
cast(`description` as STRING) as description,
cast(`labels` as ARRAY < STRING >) as labels,
to_json(`metadata`) as metadata
from
cdf_assetSubtree('lift_pump_stations:root')
where
isnotnull(`externalId`) and isnotnull(`parentExternalId`) and startswith(name, 'Pump');
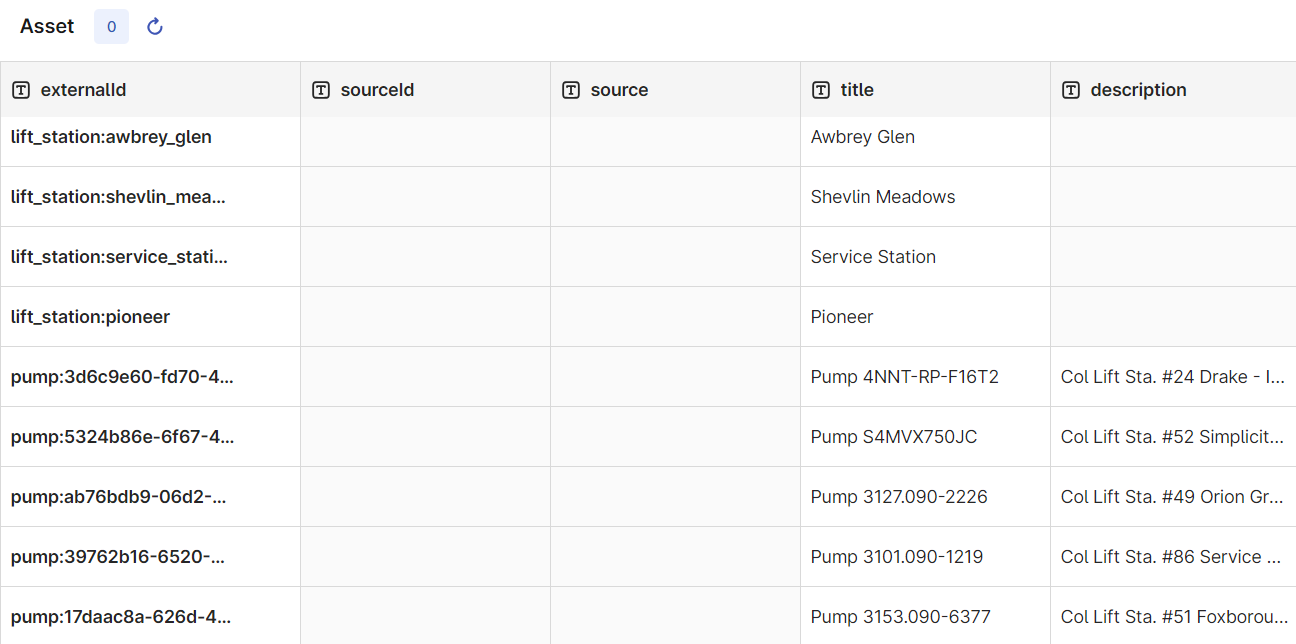
When the transformation has completed, inspect the data in CDF to verify that the lift stations and pumps have been populated in Asset model.
Use-case-specific data model
The use-case-specific data model uses the Asset, Sourceable, and Describable views from the cdf_core system space. The views are already populated through the generic asset model, and you only need to populate the new properties.
The LiftStation view already has data, but not for the new pumps property:
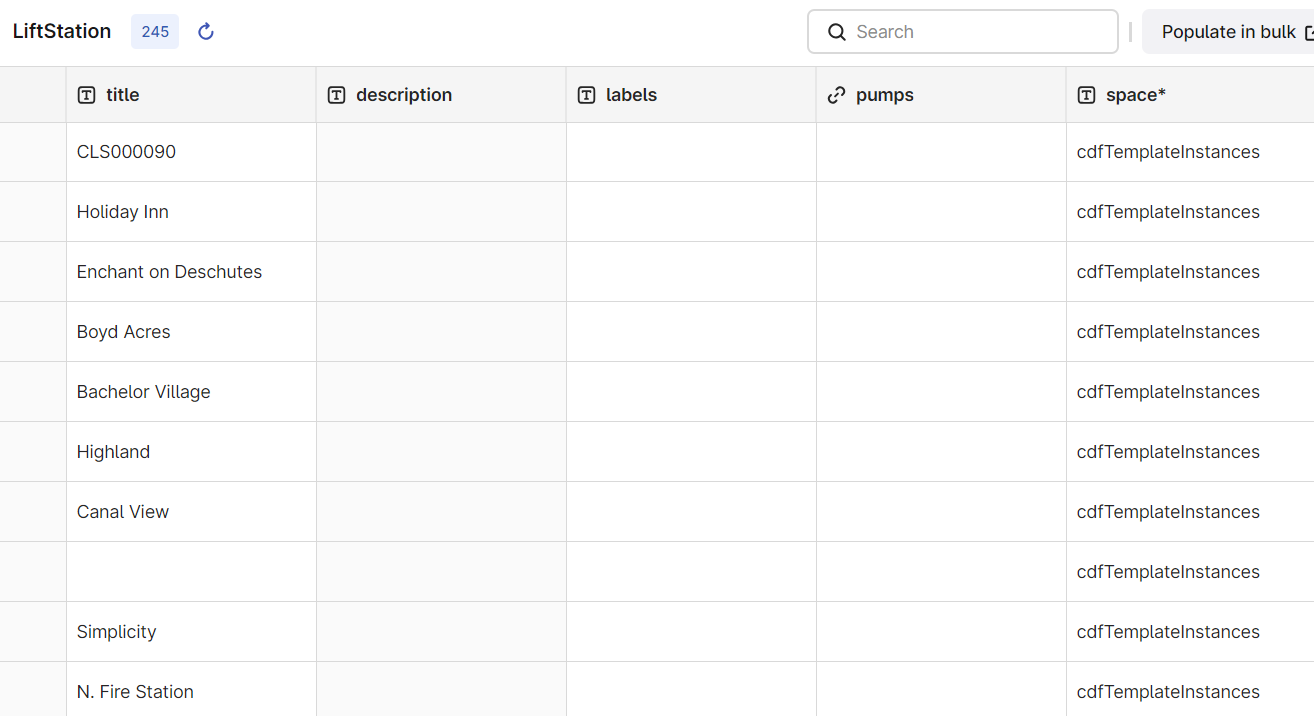
The Pump view also has data, but misses data in the new DesignPointFlowGPM, DesignPointHeadFT, LowHeadFT, and LowHeadFlowGPM properties:
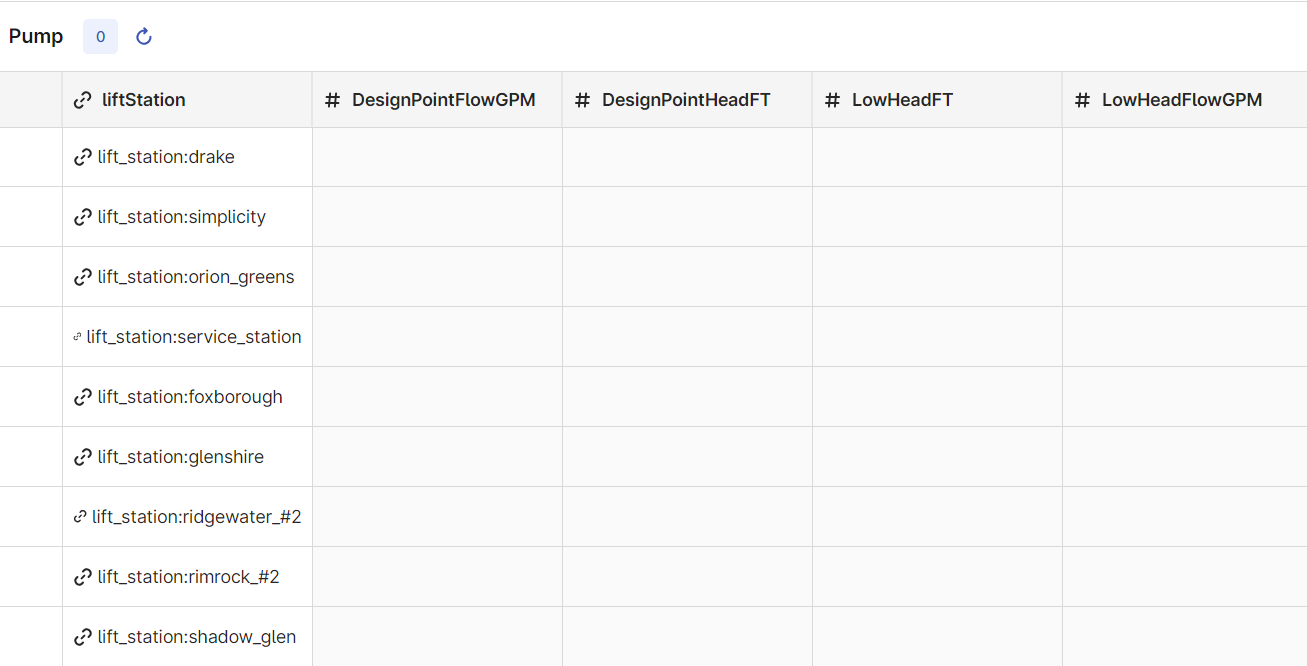
To add the missing data, the template uses one transformation to populate the pump property in the LiftStation view, and another to populate the new properties in the Pump view. Normally, the data would be in the CDF staging area, RAW, or in a CDF asset hierarchy. In this case, the template uses the existing data in the Asset container in the cdf_core system space.
To populate the pumps property in the LiftStation view, the transformation first iterates over all the assets while filtering for the pumps. Then, it creates an edge for each pump.
This is the specification for the SQL transformation:
select
concat(cast(`parent`.externalId as STRING), ':', cast(`externalId` as STRING)) as externalId,
`parent` as startNode,
node_reference('myDataSpace', cast(`externalId` as STRING)) as endNode
from
cdf_data_models("myModelSpace", "myGenericAssetModel", "1", "Asset")
where
startswith(title, 'Pump')
When the transformation has completed, inspect the data in CDF to verify that the lift stations and pumps are populated in Asset model.
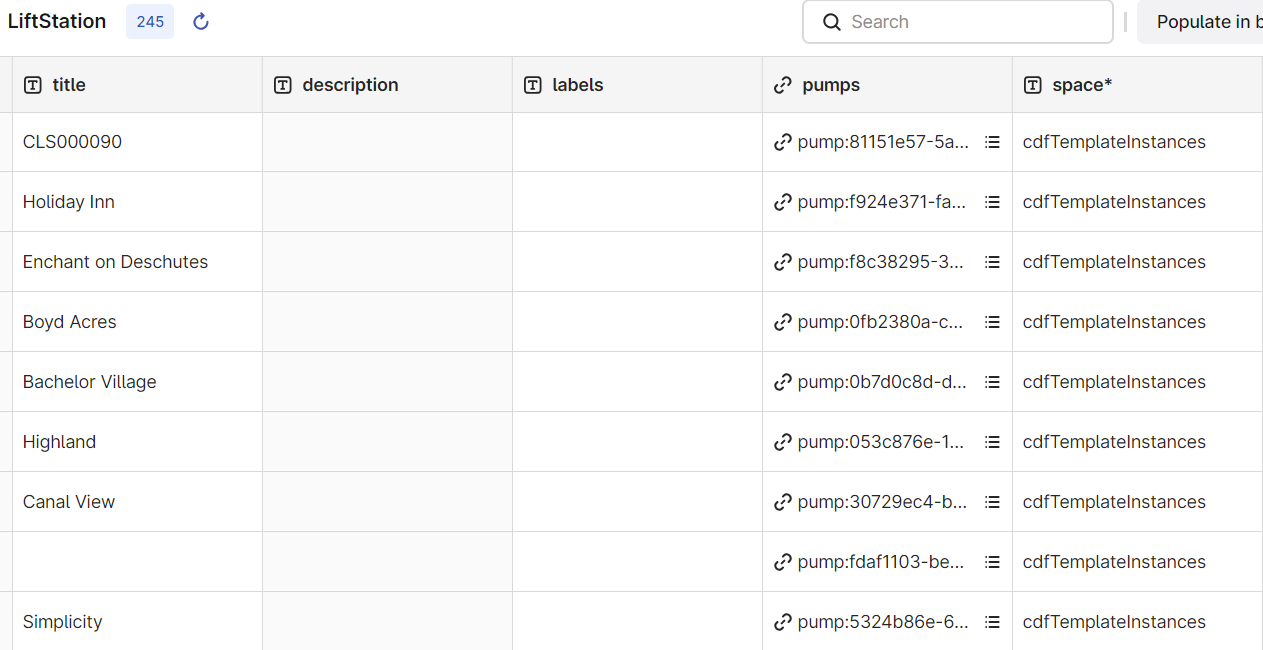
To populate the new properties in the Pump view, the transformation first iterates over all the assets while filtering for the pumps. Then, it fetches the data from the metadata property, converts it to the correct type, and writes it to the Pump container.
This is the specification for the SQL transformation:
select
cast(`externalId` as STRING) as externalId,
cast(get_json_object(`metadata`, '$.DesignPointHeadFT') as DOUBLE) as DesignPointHeadFT,
cast(get_json_object(`metadata`, '$.LowHeadFT') as DOUBLE) as LowHeadFT,
cast(get_json_object(`metadata`, '$.DesignPointFlowGPM') as DOUBLE) as DesignPointFlowGPM,
cast(get_json_object(`metadata`, '$.LowHeadFlowGPM') as DOUBLE) as LowHeadFlowGPM
from
cdf_data_models("myModelSpace", "myGenericAssetModel", "1", "Asset")
where
startswith(title, 'Pump')
When the transformation has completed, inspect the data in CDF to verify that the new properties are populated in the Pump view.
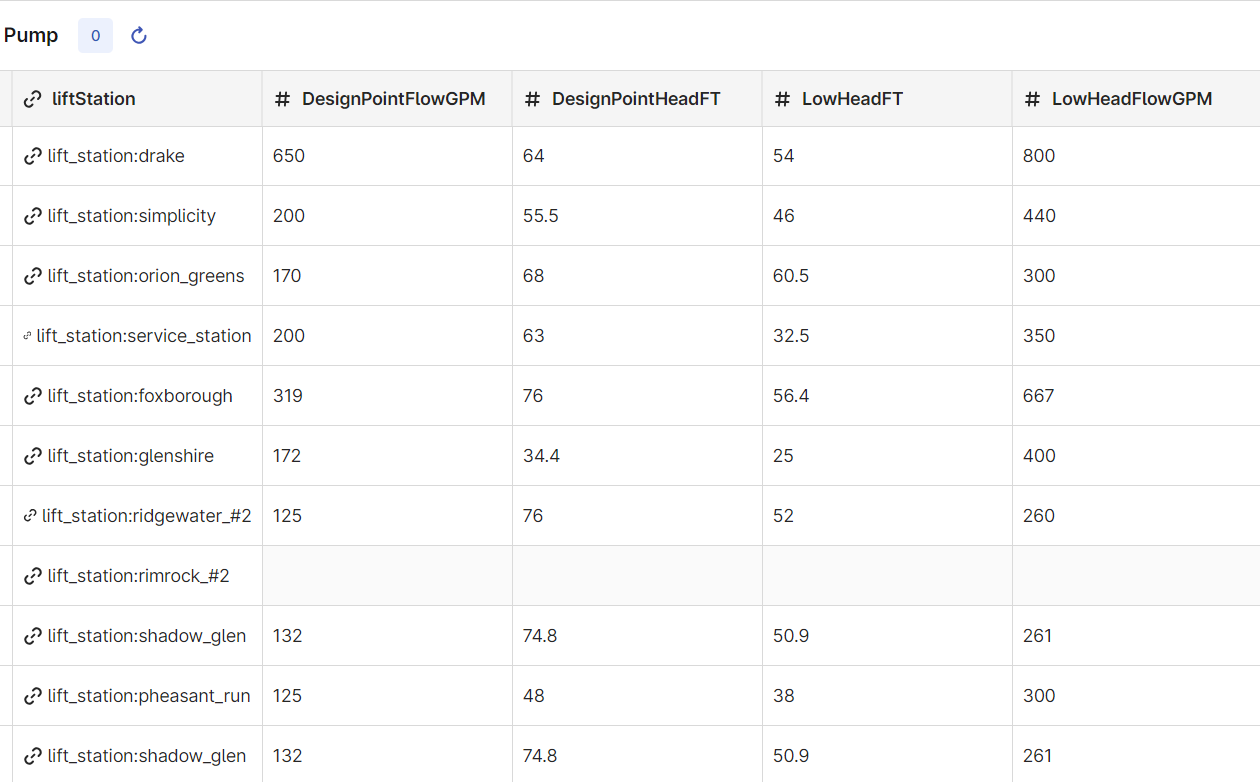
Consuming data models
Having created the data models and populated them with data, you can start consuming them. For example, you can use a GraphQL query with a range filter on the DesignPointFlowGPM property to find all the pumps with a design point flow greater than 200 GPM.
{
listPump(first: 100, filter: { DesignPointFlowGPM: { gt: 200 } }) {
items {
externalId
DesignPointFlowGPM
}
}
}
Try it
To implement the examples in this article in your own CDF project, use the cognite-toolkit Python package in the Cognite Data Fusion (CDF) templates repository.
The tools and templates in the Cognite Data Fusion (CDF) templates repository are community-supported with contributions from Cognite engineers.
Pre-requisites
- A CDF project with the necessary access.
- A Python environment project.
The toolkit uploads data to the RAW staging area and sets up the data models and transformations to populate the data models.
-
Set up your Python environment:
python -m venv venv && source venv/bin/activate. -
Install the toolkit:
pip install cognite-toolkit. -
Run the
initcommand:cdf-tk init my_project. -
Create the .env file using .env.templ as a template, in
my_project/.env.templand paste it into your current folder:.env. -
Change the content under the
localsection ofmy_project/environments.yamlto:environments.yamllocal:
project: <your-CDF project>
type: dev
deploy:
- example_pump -
Make sure you have access to the CDF project you'll be using.
-
Run
cdf-tk build my_project --env localto build the project. -
Run
cdf-tk deploy --env localto deploy the project. -
Run the transformations to populate the data models.
- Run the
pump_asset_hierarchy-load-collections_pumpto populate the asset hierarchy. - Run the
sync-asset_hierarchy_cdf_asset_source_modelto populate the generic asset data model. - Run the
pump_model-populate-pump_containerandpump_model-populate-lift_station_pumps_edgesto populate the use-case-specific data model.
- Run the