Data governance
Before you start integrating and enhancing data in Cognite Data Fusion (CDF), you should define and implement your data governance policies. Data governance is a set of principles and practices that ensure high quality through your data's lifecycle. It's a key part of data operations to continuously optimize your data management practices.
We recommend you appoint a CDF admin to work with the IT department to ensure that CDF follows your organization's security practices. Also, connect CDF to your IdP (Identity Provider), and use the existing IdP user identities to manage access to CDF and the data stored in CDF. We currently support Microsoft's Microsoft Entra ID (formerly Azure Active Directory.
This unit looks at the CDF tools and features you can use to make sure that your data conforms to your organization and users' expectations.
Secure access management
To control access to data in CDF, you define what capabilities users or applications have to work with different resource types in CDF, for example, if they can read a time series or delete an asset.
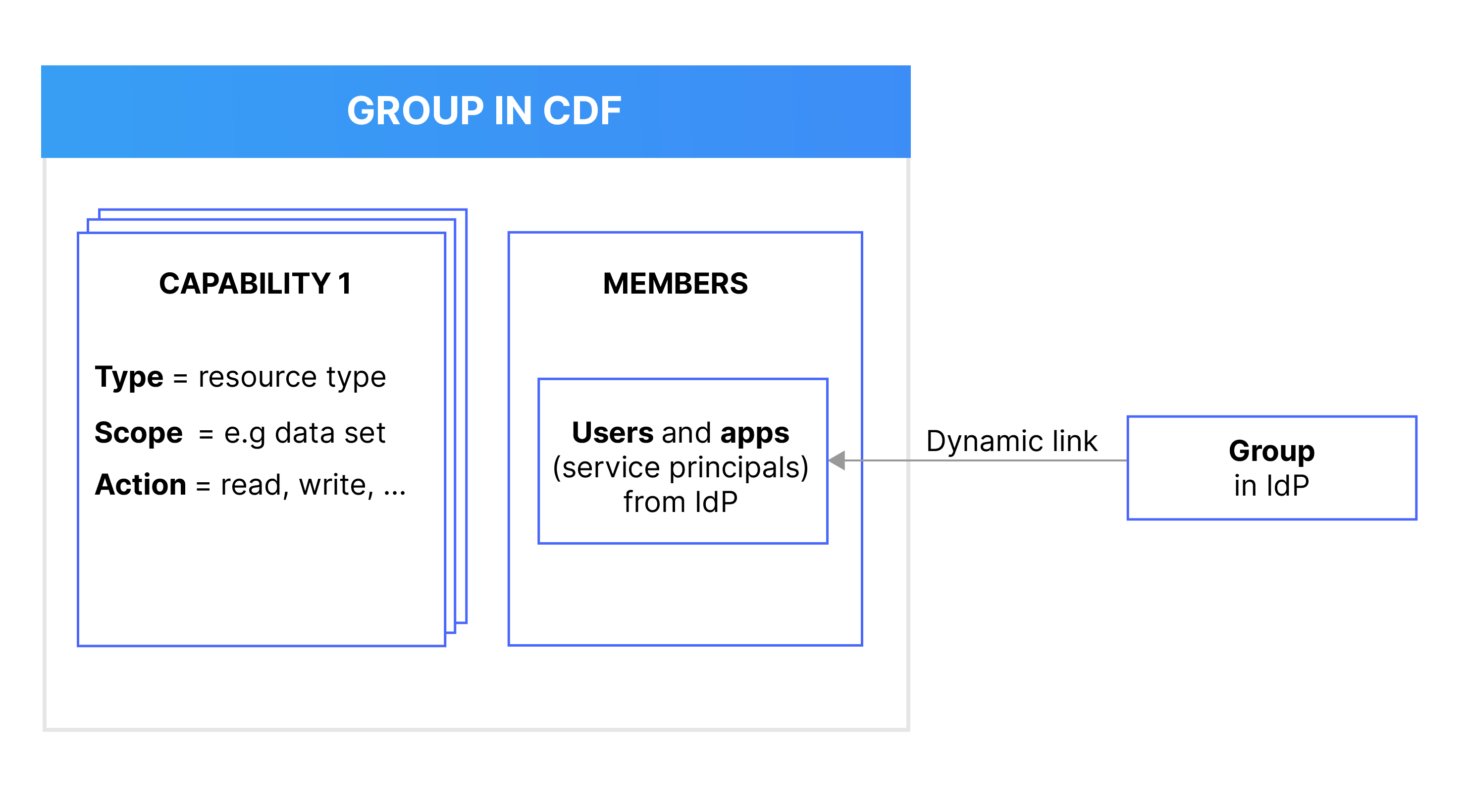
Instead of assigning capabilities to individual users and applications, you use groups in CDF to define what capabilities members (users or applications) have to work with different CDF resources. You link and synchronize the CDF groups to user groups in your identity provider (IdP), for instance Microsoft Entra ID (ME-ID).
For example, if you want users or applications to read, but not write, time series data in CDF, you first create a group in your IdP to add the relevant users and applications. Next, you create a CDF group with the necessary capabilities and then link the CDF group and the IdP group.
This flexibility lets you manage and update your data governance policies quickly and securely. You can continue to manage users and applications in your organization's IdP service outside of CDF.
Data lineage and integrity
When you rely on data to make operational decisions, it's critical that you know when the data is reliable and that end-users know when they can depend on the data to make decisions. CDF has tools and features to ensure that your data conforms to organizational and user expectations.
Data sets
Data sets let you document and track data lineage, ensure data integrity, and allow 3rd parties to write their insights securely back to your CDF project. We recommend that you organize all data in CDF in data sets to always know where data comes from and who is responsible for it.
Data sets group and track data by its source. For example, a data set can contain all work orders originating from SAP. Typically, an organization will have one data set for each data ingestion pipelines in CDF. Each data object in CDF can belong to only one data set.
A data set is a container for data objects with metadata about the data it contains. For example, you can use the data set metadata to document who is responsible for the data, upload documentation files, and describe the data lineage. In CDF, data sets are a separate resource type.
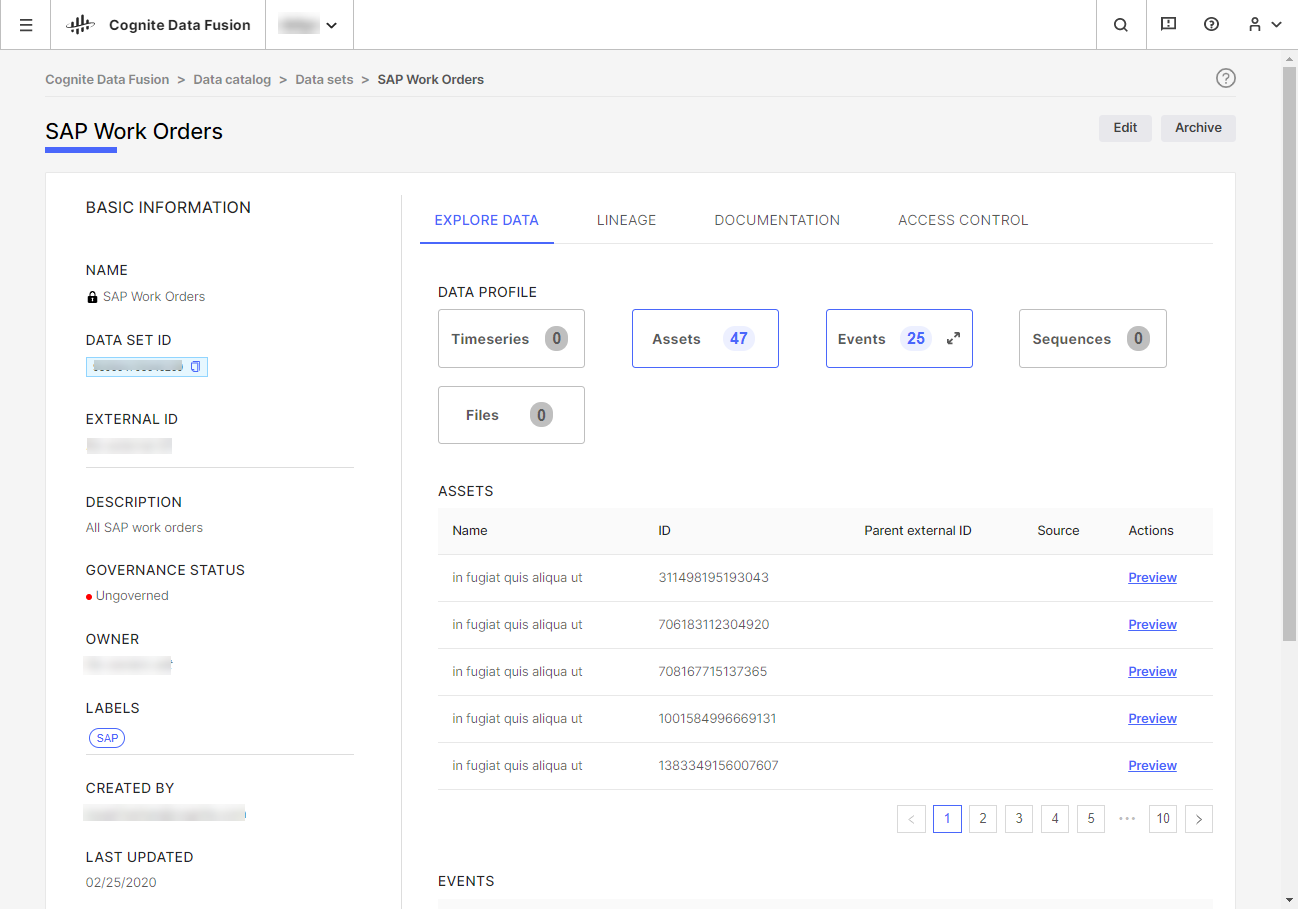
Typically, you define programmatically in the data ingestion pipelines which data objects, for example, events, files, and time series, belong to a data set. Data objects can belong to only one data set so you can unambiguously trace the data lineage for each data object.