데이터 거버넌스
Cognite Data Fusion(CDF)에서 데이터를 통합하고 개선하려면 먼저 데이터 거버넌스 정책을 정의하고 구현해야 합니다. 데이터 거버넌스는 데이터의 전체 수명 주기 동안 높은 품질을 보장하기 위한 원칙과 실무의 집합입니다. 데이터 관리 실무를 지속적으로 최적화하는 것은 데이터 운영에서 핵심적인 부분입니다.
IT 부서와 함께 작업하여 CDF가 조직의 보안 실무를 따르도록 보장하는 CDF 관리자를 지정하는 것이 좋습니다. 또한 CDF를 ID 공급자(IdP)에 연결하고 기존 IdP 사용자 ID를 사용하여 CDF 및 CDF에 저장된 데이터에 대한 액세스를 관리할 수 있습니다. Cognite는 현재 Microsoft's Microsoft Entra ID를 지원하고 있습니다.
이 단원에서는 데이터가 조직 및 사용자의 기대를 충족하도록 보장하는 데 사용할 수 있는 CDF 도구 및 기능을 살펴봅니다.
보안 액세스 관리
CDF에서 데이터에 대한 액세스를 관리하기 위해, 사용자 또는 응용 프로그램이 CDF의 다양한 리소스 유형을 사용하는 데 필요한 기능을 정의합니다. 예를 들어, 시계열 데이터 읽기, 자산 삭제 등이 여기에 포함됩니다.
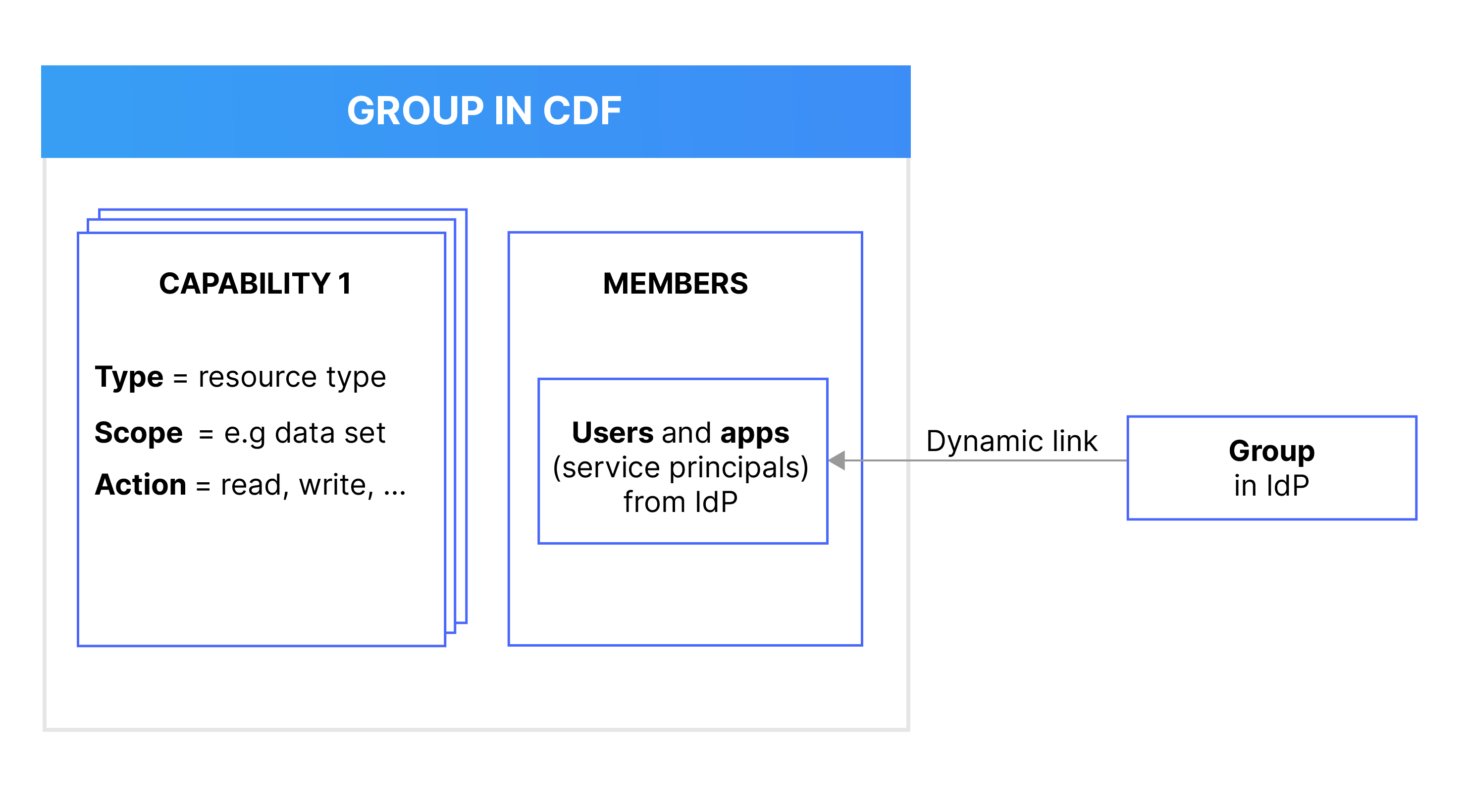
개별 사용자 및 응용 프로그램에 기능을 할당하는 대신, CDF에서 그룹을 사용하여 다양한 CDF 리소스로 작업할 때 구성원(사용자 또는 응용 프로그램)에게 필요한 기능을 정의합니다. CDF 그룹을 ~~Microsoft Entra ID (ME-ID)~~와 같은 ID 공급자(IdP)의 사용자 그룹과 연결하고 동기화합니다.
예를 들어, 사용자나 응용 프로그램을 CDF에서 시계열 데이터의 _읽기_는 가능하지만 _쓰기_는 불가능하도록 만들려면 먼저 IdP에서 그룹을 생성하고 해당 사용자와 응용 프로그램을 그룹에 추가합니다. 그런 다음 필요한 기능을 갖춘 CDF 그룹을 생성하고 해당 CDF 그룹과 IdP 그룹을 연결합니다.
이 유연한 기능을 통해 데이터 거버넌스 정책을 빠르고 안전하게 관리하고 업데이트할 수 있습니다. CDF 외부에 있는 조직의 IdP 서비스에서 사용자와 응용 프로그램을 계속 관리할 수 있습니다.
데이터 계보 및 무결성
운영과 관련된 결정을 내릴 때 데이터에 의존하는 경우 데이터의 신뢰성을 파악할 수 있는 능력이 중요합니다. 마찬가지로, 최종 사용자도 의사 결정을 내릴 때 데이터의 신뢰성을 파악할 수 있어야 합니다. CDF에는 데이터가 조직 및 사용자의 기대에 부합하는지 확인하기 위한 도구와 기능이 있습니다.
데이터 집합
데이터 집합을 사용하면 데이터 계보를 문서화하고 추적할 수 있고, 데이터 무결성을 보장할 수 있으며, 타사 공급자가 인사이트를 귀사의 CDF 프로젝트에 반영되도록 안전하게 제공할 수 있습니다. CDF에서는 데이터가 어디에서 왔으며 누가 책임을 지는지 항상 파악할 수 있도록 모든 데이터를 데이터 집합으로 구성하는 것이 좋습니다.
데이터 집합은 데이터 원본에 따라 데이터를 그룹화하고 추적합니다. 예를 들어, 한 데이터 집합에 SAP에서 발생한 모든 작업 지시가 포함될 수 있습니다. 일반적으로 조직은 CDF에서 데이터 수집 파이프라인마다 하나의 데이터 집합을 설정합니다. CDF의 각 데이터 개체는 하나의 데이터 집합에만 속할 수 있습니다.
데이터 집합은 데이터 개체에 대한 컨테이너이며 포함된 데이터와 관련된 메타데이터를 유지합니다. 예를 들어, 데이터 집합 메타데이터를 사용하여 데이터를 책임지는 담당자를 문서화하고, 설명서 파일을 업로드하고, 데이터 계보를 설명할 수 있습니다. CDF에서 데이터 집합은 별도의 리소스 유형입니다.
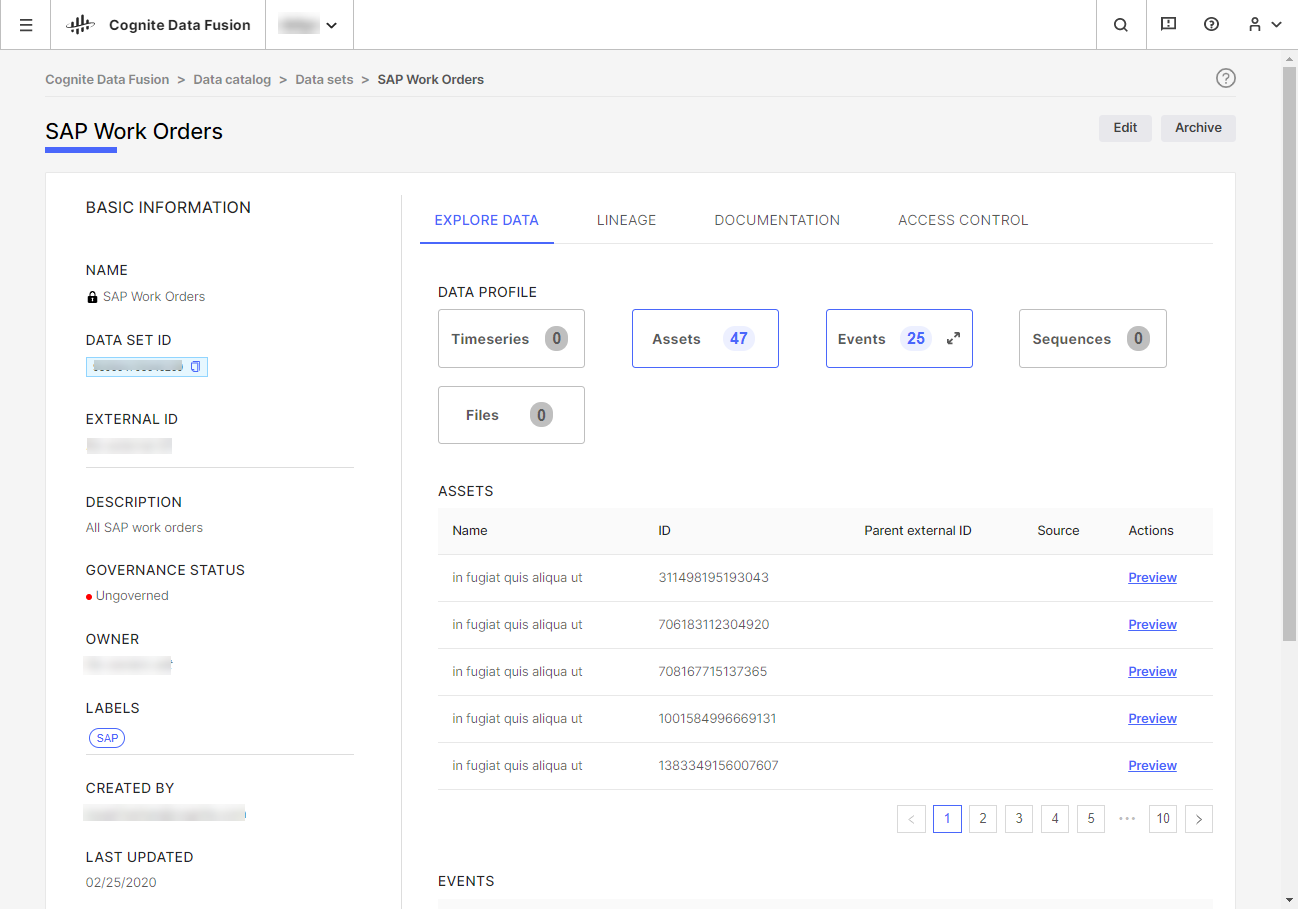
일반적으로 데이터 수집 파이프라인에서 프로그래밍 방식으로 어떤 데이터 개체(예: 이벤트, 파일 및 시계열)가 데이터 집합에 속하는지 정의합니다. 데이터 개체는 하나의 데이터 집합에만 속할 수 있으므로 각 데이터 개체의 데이터 계보를 명확하게 추적할 수 있습니다.