Datastyrning
Innan du börjar integrera och förbättra data i Cognite Data Fusion (CDF) bör du definiera och implementera dina policyer för datastyrning. Datastyrning är en uppsättning principer och metoder som säkerställer hög kvalitet genom din datas livscykel. Det är en viktig del av datadrift att kontinuerligt optimera dina datahanteringsmetoder.
Vi rekommenderar att du utser en CDF-administratör som ska arbeta med IT-avdelningen för att säkerställa att CDF följer din organisations säkerhetspraxis. Anslut också CDF till din IdP (Identity Provider), och använd befintliga IdP-användaridentiteter för att hantera åtkomst till CDF och data som lagras i CDF. Vi stöder för närvarande Microsoft's Microsoft Entra ID.
Den här enheten tittar på CDF-verktygen och funktionerna som du kan använda för att se till att din data överensstämmer med din organisations och användarnas förväntningar.
Säkra behörighetshantering
För att kontrollera åtkomsten till data i CDF definierar du vilka funktioner användare eller program har för att arbeta med olika resurstyper i CDF, t.ex. om de kan read a time series eller delete an asset.
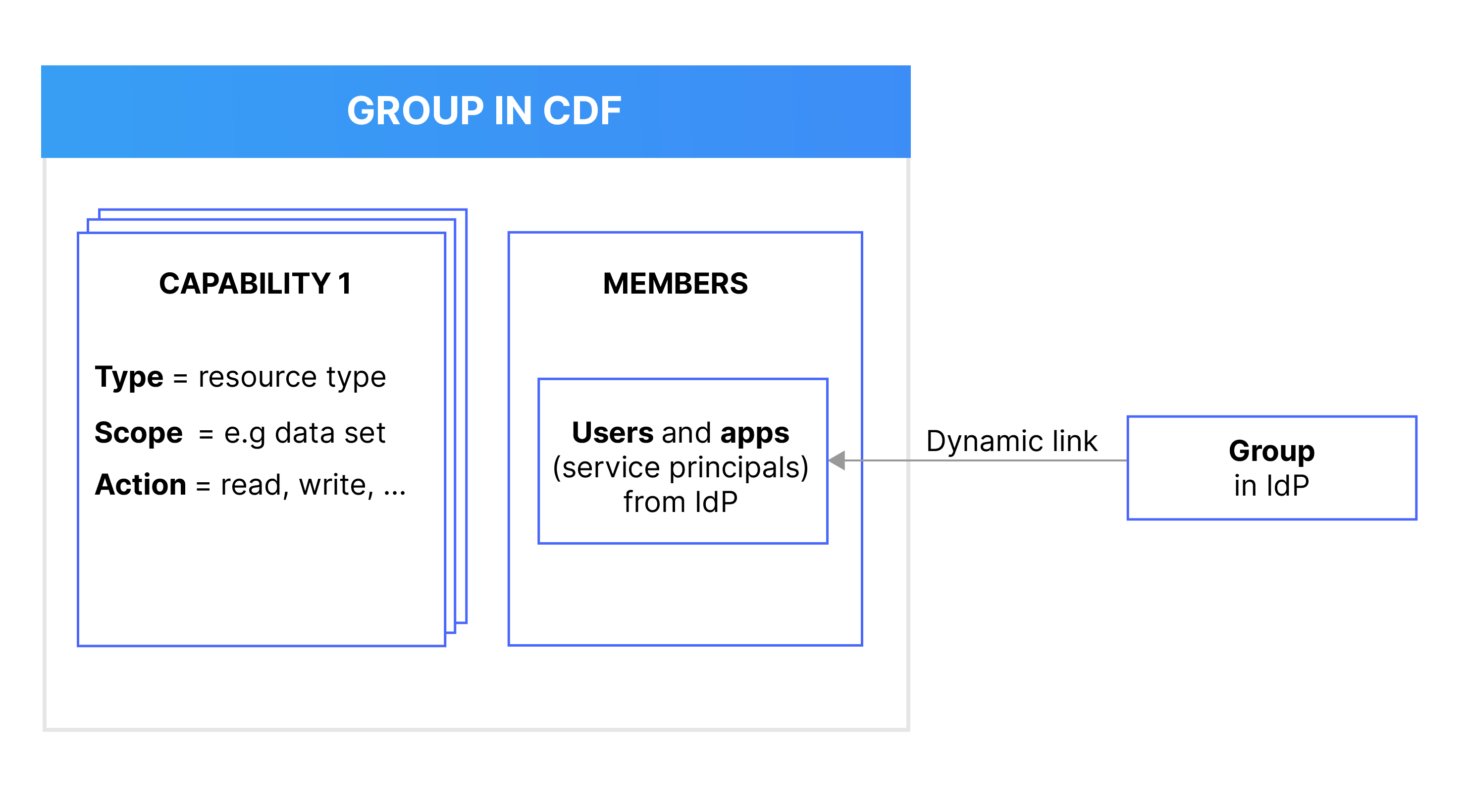
Istället för att tilldela funktioner till enskilda användare och applikationer använder du grupper i CDF för att definiera vilka kapaciteter medlemmar (användare eller applikationer) har för att arbeta med olika CDF-resurser. Din länk och synkronisera CDF-grupperna till användargrupper i din identitetsleverantör (IdP), t.ex. Microsoft Entra ID (ME-ID).
Om du till exempel vill att användare eller program ska kunna read, men inte write, tidsseriedata i CDF, skapar du först en grupp i din IdP för att lägga till relevanta användare och program. Därefter skapar du en CDF-grupp med nödvändiga möjligheter och länkar sedan CDF-gruppen och IdP-gruppen.
Denna flexibilitet låter dig hantera och uppdatera dina datastyrningspolicyer snabbt och säkert. Du kan fortsätta att hantera användare och applikationer i din organisations IdP-tjänst utanför CDF.
Datahärkomst och integritet
När du förlitar dig på data för att fatta operativa beslut är det viktigt att du vet när data är tillförlitliga och att slutanvändare vet när de kan lita på data för att fatta beslut. CDF har verktyg och funktioner för att säkerställa att din data överensstämmer med organisationens och användarnas förväntningar.
Datamängd
Med datamängder kan du dokumentera och spåra datalinje, säkerställa dataintegritet och låta tredje part skriva sina insikter säkert tillbaka till ditt CDF-projekt. Vi rekommenderar att du organiserar alla data i CDF i datamängder för att alltid veta var data kommer ifrån och vem som är ansvarig för dem.
Datamängder grupperar och spårar data efter källan. Till exempel kan en datamängd innehålla alla arbetsordrar som härrör från SAP. Normalt kommer en organisation att ha en datamängd för varje dataintagspipelines i CDF. Varje dataobjekt i CDF kan endast tillhöra en datamängd.
En datamängd är en behållare för dataobjekt med metadata om de data den innehåller. Du kan till exempel använda datamängden metadata för att dokumentera vem som är ansvarig för data, ladda upp dokumentationsfiler och beskriva datamängden. I CDF är datamängder en separat resurstyp.
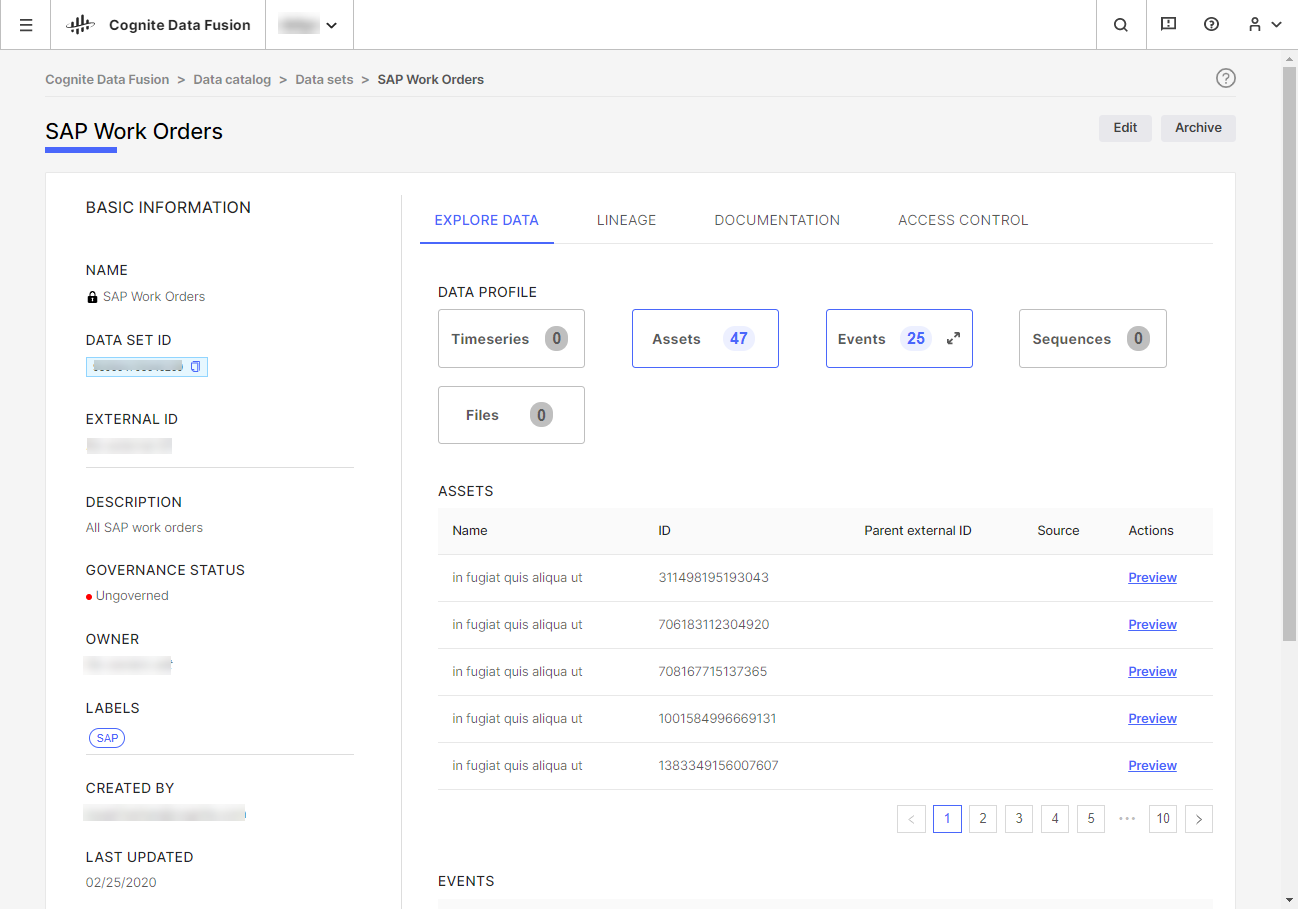
Vanligtvis definierar du programmatiskt i datainmatningspipelines vilka dataobjekt, till exempel händelser, filer och tidsserier, som tillhör en datamängd. Dataobjekt kan bara tillhöra en datamängd så att du entydigt kan spåra datalinjen för varje dataobjekt.