Customizing modules
The CDF Toolkit includes reusable modules tested in real customer projects. The modules demonstrate best practices and patterns for establishing access control and addressing common configuration tasks in Cognite Data Fusion.
In most cases, you can use the modules as-is or copy and adapt them to fit your requirements. This article describes the design of the example modules. Use the information as guidelines to create custom modules or to adjust the existing ones.
Modules
A module is a bundle of logically connected resource configuration files, each of which sets up one CDF resource type with the minimum required access controls. For example, a module can contain resource configuration files to set up the necessary extractors, extraction pipelines, data sets, and transformation resources for a complete data pipeline.
Other use cases for modules include:
- Transfer data between different data structures.
- Contextualize data.
- Set up the required resources for an application, such as InField.
- Load static demo data.
In general, modules should be self-contained and not rely on external resources. In some cases, referring to resources outside of the module makes sense. However, inter-module dependencies often come at the cost of maintainability, and you should avoid them if possible.
Directory structure and naming standards
Establishing a directory structure and naming standard for modules and configuration files is vital to successfully deploying and administering CDF projects with the CDF Toolkit.
Module directory structure
Each module is implemented as a directory in the file system. The directory's name describes the content or the purpose of the module. Use lowercase for the name and underscores to separate words.
For example, a module that sets up the required resources to transfer asset data from a source system called "Scada" in the "Springfield" location could be named springfield_scada_asset_data_pipeline. To add more information, create a README.md file in the module directory.
Modules contain YAML configuration files that describe the resources needed to solve the task, including access groups. The CDF Toolkit requires that the YAML files are stored in subdirectories according to the resource type they describe. For an overview of the default resource hierarchy, see the reference section.
Example module structure for a data pipeline:

To organize large modules, the CDF Toolkit accepts additional directory levels with arbitrary names:
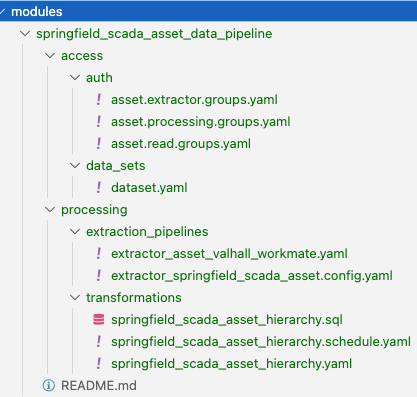
In both the examples above, the config.[env].yaml file needs only to mirror the path to the module, not its content:
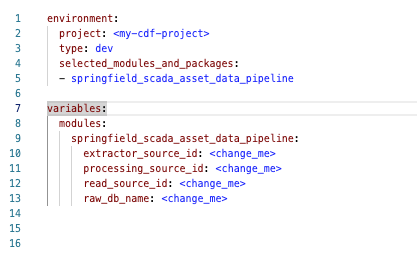
Resource configuration files (YAML)
To establish logical coherence across modules in Cognite Data Fusion, we highly recommend using the external IDs and following the naming conventions in your configuration files. The CDF Toolkit accepts configurations that don't follow these recommendations but will display warnings.
The structure of the YAML resource configuration files matches the Cognite Data Fusion API specification. The required formats are described in the YAML configuration reference article.
To include an existing CDF resource in a module, you can use the Python SDK to export it to a YAML file using the dump_yaml() method. See the Python SDK documentation for more information.
With a few exceptions, you can describe all resources as a list or a single instance in a YAML file:
Option 1:
# first.dataset.yaml
externalId: df_asset_{{location}}
description: 'Asset data from {{location}}'
# second.dataset.yaml
externalId: df_files_{{location}}
description: 'Files from {{location}}'
Option 2:
# my.datasets.yaml
- externalId: df_asset_{{location}}
description: 'Asset data from {{location}}'
- externalId: df_files_{{location}}
description: 'Files from {{location}}'
Security
Access control should be self-contained within each module. You need to configure which roles (groups) each module requires and which resources the groups can access.
Follow the principle of least privilege and allow each module to access only the information and resources necessary for its purpose. A module can have multiple groups, but those groups should not have access to resources defined outside of the module.
Changing a Cognite Data Fusion project requires elevated privileges (example). Using elevated groups requires strict governance and should not be available to individual contributors in production environments or other environments containing sensitive data. Instead, approval mechanisms and dedicated IdP service principals/accounts should be established.
Example:
# waterdata.reader.group.yaml
name: gp_waterdata_reader
sourceId: '{{ waterdata_reader_source_id }}'
description: ''
metadata:
origin: cdf-project-templates
sourceName: '{{ waterdata_reader_source_name }}'
capabilities:
- dataModelsAcl:
actions:
- READ
scope:
spaceIdScope:
spaceIds:
- sp_waterdomain_data
- sp_waterdomain_models
- dataModelInstancesAcl:
actions:
- READ
scope:
spaceIdScope:
spaceIds:
- sp_waterdomain_data
- sp_waterdomain_models
- datasetsAcl:
actions:
- READ
scope:
idScope:
ids:
- ds_waterdomain
- ds_hydrology
- assetsAcl:
actions:
- READ
scope:
datasetScope:
ids:
- ds_waterdomain
- ds_waterprep
- ds_hydrology
- filesAcl:
actions:
- READ
scope:
datasetScope:
ids:
- ds_waterdomain
- ds_waterprep
- ds_hydrology
The datasets, spaces, and RAW databases should be known to the module.
Note that idscopes uses the external ID, while the API uses the internal ID. The CDF Toolkit resolves the external ID to the internal ID before sending the request to the CDF API to make the configuration transferrable between environments.