Availability and business continuity
Service availability
We measure availability and performance metrics on specific tenants or CDF clusters per month, excluding downtime for maintenance. Availability refers to the fraction of valid requests that return successful responses during a calendar month.
Response codes and requests are aggregated over a calendar month, but traffic during maintenance windows is excluded from the calculation. We also make necessary adjustments to consider downtime resulting in zero traffic.
Maintenance and updates
We continuously release software updates and perform maintenance to keep services running smoothly. Updates are part of the continuous platform operation and don't require announcements or approvals.
Some services might be unavailable during maintenance windows.
We announce maintenance at least two weeks in advance and post notifications in the appropriate channels. We will work with you to agree on the best time for maintenance to minimize the impact on your production environments.
Because many clusters are multi-tenant, there is a chance that we can't accommodate all requests. In those cases, we must reserve the right to complete maintenance at the originally scheduled time.
Application availability
We measure application availability by the fraction of 1-minute intervals during a calendar month where:
- less than 5% of the end-user page views are served with errors.
- at least 90% of load time is less than 20 seconds.
The error rate is measured across CDF projects and from the server that runs the application.
Load time is measured on specific bookmarks for important pages in the application.
Calculations exclude maintenance windows.
API availability
We measure API availability by the fraction of valid requests that result in a successful response during a calendar month. Traffic that results in response code 429 is ignored. Calculations subtract the periods when the system is down for maintenance.
To calculate availability, we subtract the fraction of the months that have unplanned downtime from the success rate outside the planned maintenance windows. We don't consider the time and traffic during the maintenance windows.
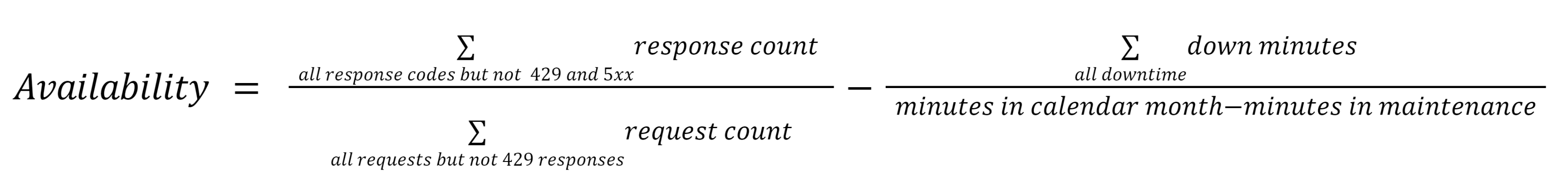
Down minutes refers to the number of minutes during a month with zero traffic on the API gateway.
Extractors
You can see which extractors we support integration with by looking at the list of extractors in the CDF user interface. Extractors run on 3rd party operating systems and networks in your company environments.
You are responsible for downloading and deploying maintenance releases based on assessments communicated in CDF release notes or advice from Cognite Support.
When we deprecate an API, you must be aware of the deprecation of old extractor versions. We offer new versions and updated documentation of components interfacing with Cognite APIs in a reasonable time before the deprecation of an API version. In those cases, you must install and use the current versions and releases of the extractors.
Backup and restore
We ensure that data for all resource types is backed up. See resource types for more information. Backup frequency and retention are listed below. Backups are encrypted at REST, and stored in geo-redundant storage services provided by our cloud providers. Sometimes, our cloud providers handle the backups. Cognite will always use services that have backups stored in two different data centers, and in different regions when possible. Cognite's backups are stored in at least two different availability zones (Azure) or two regions (AWS and Google) when available.
The tables show the frequency and retention of backups for resource types and the worst-case estimated time to restore the data. These tables only apply to backup restore Scenario A described under Request data restore.
Multi-tenant cluster backup and restore
| Resource type | Data type | Backup frequency | Retention | Restore |
|---|---|---|---|---|
| Authentication | All | Daily | 6 weeks* | 1 business day |
| Assets | All | Daily | 6 weeks* | 5 business days |
| Data modeling** | All | Daily | 6 weeks* | 5 business days |
| Events | All | Daily | 6 weeks* | 5 business days |
| Files | Metadata | Daily | 6 weeks* | 5 business days |
| Files | File content | Daily | 6 weeks* | 5 business days |
| Time series and sequences | All | Weekly | 6 weeks | 5 business days |
| 3D models | Model data | Daily | 6 weeks* | 5 business days |
| Application user settings (InField) | User-made configurations, lists, charts, and settings | Daily | 28 days | 1 business day |
| Audit logs | Logs | Continuous | 400 days | 5 business days |
| Relationships | All | Daily | 6 weeks* | 5 business days |
| Annotations | All | Daily | 6 weeks* | 5 business days |
| Labels | All | Daily | 6 weeks* | 5 business days |
| Entitymatching, and engineering diagrams | All | Daily | 6 weeks* | 5 business days |
| Extpipes | All | Daily | 6 weeks* | 5 business days |
| Functions | All | Daily | 6 weeks* | 5 business days |
| Templates | All | Daily | 6 weeks* | 5 business days |
| Geospatial | All | Daily | 6 weeks* | 5 business days |
*Backup and retention time for these resource types is 35 days in Azure-based CDF clusters. **Restore is only available for scenario A (see below).
Single-tenant cluster backup and restore
The following table describes the backup frequency, retention, and restore time targets valid for customers on a dedicated single-tenant CDF cluster.
| Resource type | Data type | Backup frequency | Retention | Restore |
|---|---|---|---|---|
| Authentication | All | Daily | 6 weeks* | 1 business day |
| Assets | All | Daily | 6 weeks* | 1 business day |
| Data modeling | All | Daily | 6 weeks* | 1 business day |
| Events | All | Daily | 6 weeks* | 1 business day |
| Files | Metadata | Daily | 6 weeks* | 1 business day |
| Files | File content | Daily | 6 weeks* | 1 business day |
| Time series, and sequences | All | Weekly | 6 weeks | 1 business day |
| 3D models | Model data | Daily | 6 weeks* | 1 business day |
| Application user settings (InField) | User-made configurations, lists, charts, and settings | Daily | 28 days | 1 business day |
| Audit logs | Logs | Continuous | 400 days | 1 business day |
| Relationships | All | Daily | 6 weeks* | 1 business day |
| Annotations | All | Daily | 6 weeks* | 1 business day |
| Labels | All | Daily | 6 weeks* | 1 business day |
| Entitymatching, and engineering diagrams | All | Daily | 6 weeks* | 1 business day |
| Extpipes | All | Daily | 6 weeks* | 1 business day |
| Functions | All | Daily | 6 weeks* | 1 business day |
| Templates | All | Daily | 6 weeks* | 1 business day |
| Geospatial | All | Daily | 6 weeks* | 1 business day |
*Backup and retention time for these resource types is 35 days in Azure-based CDF clusters.
Alternatives to restoring data from backups
Time series and sequences
The time series and sequences data are stored in FoudationDB databases with a replication factor of 3. Data are stored across 3 different storage servers, which allows geo-redundancy by locating servers in more than one data center. The FoundationDB configuration used also provides versioning for the data points stored. Versioning lets Cognite roll back the data for a CDF project to the state it had at a specified time: "last known good". The time resolution offered is 1 minute within the last 7 days.
The combination of the replication factor and the versioning feature lets Cognite roll back to the last known good data for a customer in all situations where the data integrity was broken by a user mistake, programming mistake, or service malfunction. The geo-redundant replications also protect the data in cases where the public cloud provider loses a data center. These investments in resiliency were made to address the 1 week increase in RPO coming from the weekly backup cadence of time series and sequences.
Point-in-time restore
The resource types not stored in FoundationDB are stored in PostgreSQL. Backups run every 24 hours, and point-in-time restore is enabled. This enables the restore of individual backups to the same point in time to ensure that the data model is consistent after restoration.
Point-in-time restore is available for situations where backups are available in the main region of the CDF cluster.
Request data restore
There are two scenarios for restoring data:
-
Scenario A - Incident: Disaster recovery after an incident with a root cause outside your control.
-
Scenario B - Request: Backup/restore after a user mistake that has corrupted data.
The party responsible for recovery depends on the incident's root cause.
We can manage the request for restoring data in scenario B when the responsible party covers the time and material costs (labor costs and service fees) for the data restore work. Data restore in scenario B will only involve restoring data stores to a state found at a time prior to the incident triggering the request. Data can only be restored to the original project. We don't offer cross project restore. Cognite won't offer additional processing of data.
To request data restore
-
Submit a request to Cognite support asking for data recovery.
The request must contain detailed descriptions explaining:
- What data needs to be restored. This must be specified by a listing of the resource types that should be restored.
- Recovery Point Target Time: The point in time when the data was deleted or corrupted. Cognite will restore data to a point in time as close as we can get BEFORE the specified Recovery Point Target Time.
- The URL name and project ID of the CDF project to restore data to.
- The request must contain an approval allowing Cognite to block access to the CDF project during the restore operation.
- The request must contain an approval allowing Cognite to delete all data that's newer than the Recovery Point Target Time. The customer needs to give Cognite permission to delete data of the specified resource types listed in 1.1 that the customer has updated or created after the time specified in 1.2.
-
You receive a reply with a time and material estimate and a plan for how the restore will happen.
-
We start the data restore when the cost estimate and the plan are accepted.
We can't promise that this data restore will happen as quickly as the restore times indicated in the overview tables, which only apply to scenario A.