About extraction pipelines
To make sure you have reliable and trustworthy data in Cognite Data Fusion (CDF) data sets, set up extraction pipelines to monitor the data flow. By activating automatic email notifications, you'll catch any extractor failures or data flow interruptions and can start troubleshooting using the extraction pipeline documentation.
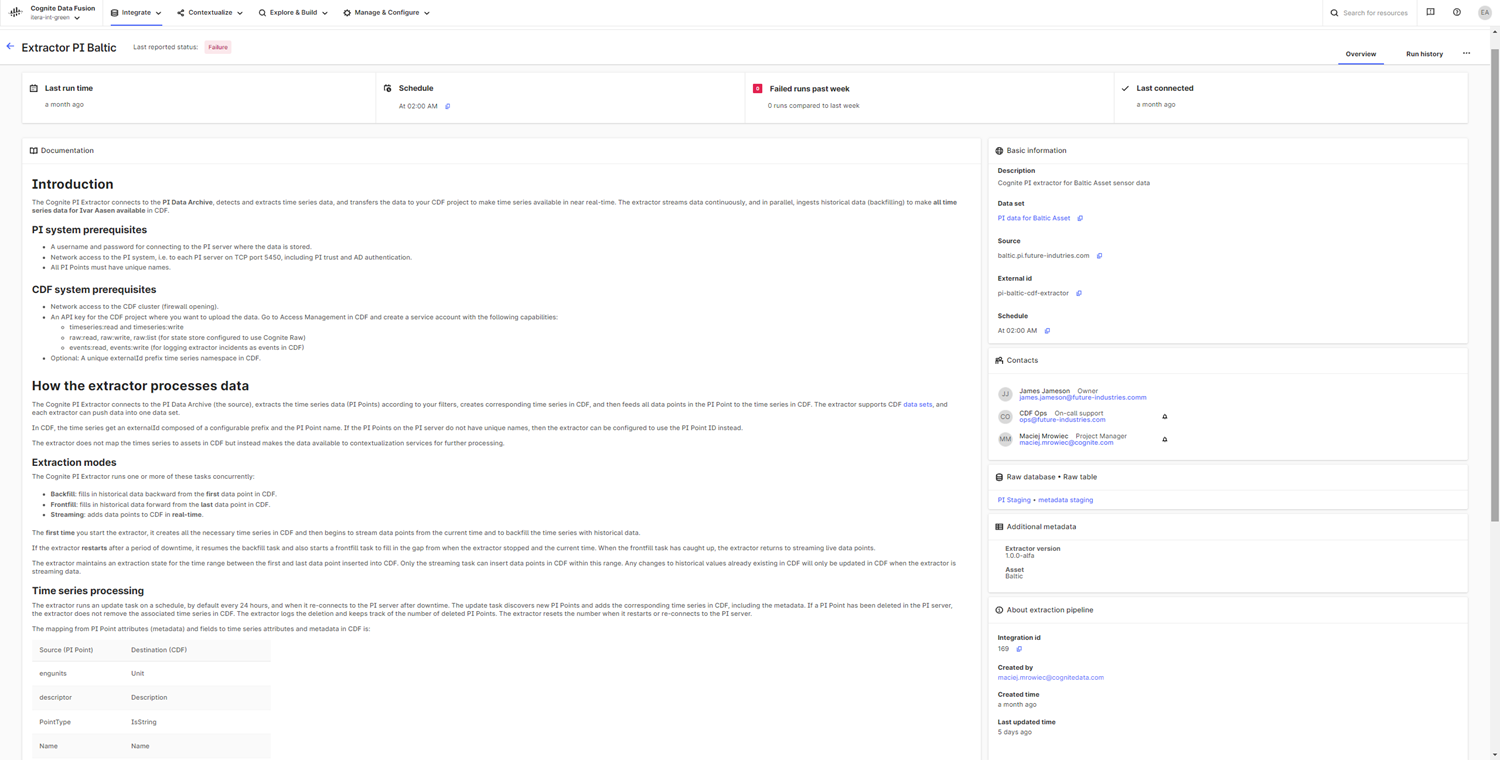
You can create and monitor extraction pipelines while you're already working with CDF data sets by opening Data management > Data catalog. You can also create and view pipelines across several data sets from Data management > Integrate > Extraction pipelines.
On the Extraction pipeline page, you'll get an overview of successful and failed pipeline runs, see when an extractor last communicated with CDF, and the last data sync with CDF. You can contact the pipeline owner and other relevant stakeholders using the contact info added for a pipeline. The extraction pipelines documentation helps you keep track of the data set, source systems, target database tables, and comprehensive free-text descriptions will guide you through the troubleshooting.
In the Configuration settings for extraction section, you can create and edit the extractor configuration to test and verify the extractor settings, preferably in testing and staging environments. When applying the extractor configuration to a production environment, we recommend setting up remote configuration files stored in the cloud using versioned files and continuous integration systems, such as GitHub Actions, or directly with the Cognite API.
You can set up extraction pipelines for all types of extractors, such as data flows from Azure Data Factory and the Cognite extractors.