Set up extraction pipelines
This article explains how you create extraction pipelines for all types of extractors you want to monitor via extraction pipelines. You need to add data set, name, and external ID on the Create extraction pipeline page. You can add or edit additional information later on the Extraction pipelines overview page.
Before you start
-
A data set must exist for the data you want to add to an extraction pipeline.
-
Navigate to Access and set any of these capabilities for users, extractors, and third-party actors, such as GitHub Actions:
| User | Action | Capability | Description |
|---|---|---|---|
| End-user | Create and edit extraction pipelines | extractionpipelines:write | Gives access to create and edit individual pipelines and edit notification settings. Ensure that the pipeline has read access to the data set being used by the extraction pipeline. |
| View extraction pipelines | extractionpipelines:read | Gives access to list and view metadata of the pipeline. | |
| Create and edit extraction configurations | extractionconfigs:write | Gives access to create and edit an extractor configuration in an extraction pipeline. | |
| View extraction configurations | extractionconfigs:read | Gives access to view an extractor configuration in an extraction pipeline. | |
| View extraction logs | extractionruns:read | Gives access to view run history reported by the extraction pipeline runs. | |
| Extractor | Read extraction configurations | extractionconfigs:read | Gives access to read an extractor configuration from an extraction pipeline. |
| Post extraction logs | extractionruns:write | Gives access to post run history reported by the extraction pipeline runs. | |
| Third-party actors | Create and edit extraction pipelines | extractionpipelines:write | Gives access to create and edit individual pipelines and edit notification settings. Ensure that the pipeline has read access to the data set being used by the extraction pipeline. |
| Create and edit extraction configurations | extractionconfigs:write | Gives access to create and edit the extractor configuration from an extraction pipeline. |
Create extraction pipelines
-
Navigate to Data management > Integrate > Extraction pipelines, or
Data management > Data catalog. Then select a data set and open the Lineage tab to add a pipeline to the selected data set.
-
Select Create extraction pipeline, where you will be requested to fill in the mandatory fields for creating a pipeline.
- Select Create to open the Extraction pipeline overview. On this page, you can add additional information to give contexts and insights about the pipeline.
You'll see successful or failed runs when the connected extractor starts ingesting data into CDF. See the extractors' configuration articles for setup.
Enable email notifications
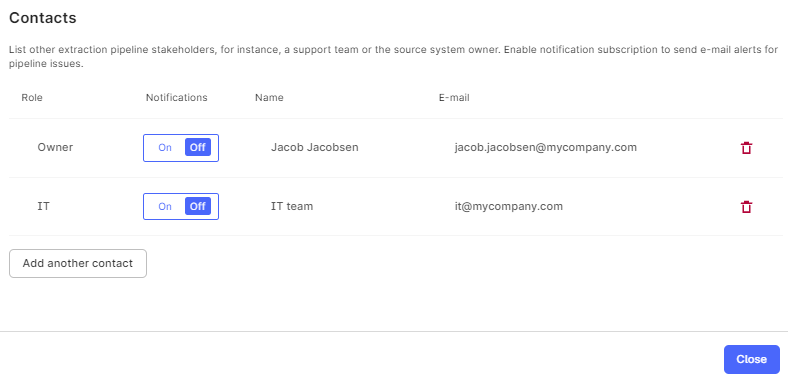
Data owners and other stakeholders can receive email notifications about the extraction pipeline runs. The notifications are triggered when an extraction pipeline reports a failed run to CDF or an extraction pipeline with continuous data flow stops communicating with CDF. The notification is sent when a predefined time condition is reached.
- Under Contacts, enter the email address for the data owner.
- Optionally, add other contacts for the extraction pipeline.
- Turn on the Notification toggle.
- Select Confirm.
Email notifications are only sent when an extraction pipeline status changes state or CDF has not registered any communication with the pipeline after a predefined time condition. This is to prevent multiple emails for ongoing incidents.
For new incidents, emails are only sent for the first reported failed run and when the incident is resolved. Multiple reported failures in succession are ignored.
Edit the extractor configuration file
When you set up the Cognite extractors, you must create a configuration file that fits your requirements. Refer to the extractor documentation for details.
You can create or edit the configuration in the Configuration file for extractor section to test and verify the settings, preferably in testing and staging environments. When applying the configuration to a production environment, we recommend setting up remote configuration files stored in the cloud using versioned files and continuous integration systems, such as GitHub Actions, or directly with the Cognite API.
- Select Create configuration to create a file or copy and paste an existing file onto the canvas.
- Make your changes and select Publish to save. The extractor now reads the configuration from CDF.
- Test and verify the changed settings in the upcoming extractor run.
- Deploy the changed settings in a production environment, for instance, by committing the configuration file to GitHub for versioning and a continuous integration pipeline using GitHub Actions.
Best practice for documenting extraction pipelines
It is good practice to enter comprehensive information about a pipeline to simplify troubleshooting and administration of pipelines. The minimum information you need to record is Data set, Name, and External ID.
Monitor the pipeline status by setting up email notifications for failed and interrupted pipelines and add contact details for the pipeline owner and other stakeholders. You'll find the switch for activating email notifications when you add a contact.
Select the schedule set up in the extractor to document how often the extractor is expected to update the data in CDF and check the Last connected to make sure CDF and the extractor are communicating. It's useful to record the source system name and the RAW database tables to keep track of where your data is extracted from and ingested into.
Information specific to your organization can be added using the metadata fields with key/value pairs.
You can enter all contexts and other insights about the pipeline to speed up troubleshooting issues. Enter free text using the Documentation field for this purpose. This is displayed as a ReadMe section on the Extraction pipeline overview page. Make sure to keep this content updated at all times. You can format the text using Markdown.