Use Functions
Functions lets you deploy Python code to Cognite Data Fusion (CDF), call the code on-demand, or schedule the code to run at regular intervals.
Authentication with OpenID Connect
With OpenID Connect, you can instantiate your CogniteClient with either an OpenID Connect user token or client credentials.
Authenticate with an OpenID Connect user token
client = CogniteClient(project="my-project", token=my_token)
my_token is a string or a callable.
Authenticate with client credentials
For more information see authenticate with client credentials on Python. To instantiate your CogniteClient with client credentials:
from cognite.client import CogniteClient, ClientConfig
from cognite.client.credentials import OAuthClientCredentials
# This value may change depending on the cluster your CDF project runs on
base_url = "https://api.cognitedata.com"
tenant_id = "my-tenant-id"
creds = OAuthClientCredentials(
token_url=f"https://login.microsoftonline.com/{tenant_id}/oauth2/v2.0/token",
client_id="my-client-id",
client_secret="my-client-secret",
scopes=[f"{base_url}/.default"]
)
cnf = ClientConfig(
client_name="custom-client-name",
project="cdf-project-name",
credentials=creds,
base_url=base_url
)
client = CogniteClient(cnf)
Create a function
You can create a function from a Jupyter Notebook, a folder, an uploaded zip file, or from CDF. The examples below assume that you have the Python SDK installed in your environment.
Create a function from a Jupyter Notebook
To create a function from a Jupyter Notebook, refer directly to the Python function named handle. This is the easiest way to get started but it's only suitable for short and simple functions.
The function_handle argument points to the handle function defined in the example below, and the name in the definition must be handle.
When you deploy with the function_handle argument, you must import within handle(). In other cases (with the folder or file_id arguments), the imports can be outside handle().
To create a Function with dependencies, see the Python SDK documentation.
Example:
- Define the following function in your notebook:
def handle(client, data):
asset_no = data["assetNo"]
print("Returning asset number {}".format(asset_no))
assets = client.assets.list()
return {"assetName": assets[asset_no].name}
- Deploy it to CDF:
from cognite.client import CogniteClient, ClientConfig
from cognite.client.credentials import OAuthClientCredentials
# This value would change depending on the cluster where your CDF projects runs on
base_url = "https://api.cognitedata.com"
tenant_id = "my-tenant-id"
creds = OAuthClientCredentials(
token_url=f"https://login.microsoftonline.com/{tenant_id}/oauth2/v2.0/token",
client_id="my-client-id",
client_secret="my-client-secret",
scopes=[f"{base_url}/.default"]
)
cnf = ClientConfig(
client_name="custom-client-name",
project="cdf-project-name",
credentials=creds,
base_url=base_url
)
client = CogniteClient(cnf)
# Create the function
func = client.functions.create(
name="my-function",
external_id="my-function",
function_handle=handle
)
The function_handle argument points to the handle function defined above, and the name in the definition must be handle.
When you deploy with the function_handle argument, you must import within handle(). In other cases (with the folder or file_id arguments), the imports can be outside handle().
Create a function from a folder
For more advanced functions, you can define your function in a module that imports other modules. To create a function, replace the function_handle argument with the folder argument and set it equal to the path of the folder containing your code.
Example:
from cognite import CogniteClient
client = CogniteClient(project="my-project", token="my-token")
func = client.functions.create(
name="my-function",
external_id="my-function",
folder="path/to/folder"
)
Your modules inside path/to/folder can have nested imports of arbitrary depth. The only requirement is the file called handler.py (assumed to be in the root folder unless otherwise specified) and a function named handle within this module. This serves as the entry point to the function.
If your handler.py file isn't in the root folder, you must specify its location via the argument function_path (defaults to handler.py).
If your function depends on other packages, you can list these packages in a requirements.txt file. You must place the file in the root folder. These packages will be pip installed when the function is deployed.
Create a function from an uploaded zip file
You can also upload a zip file containing the function code directly to the files API and refer to its id when you create the function.
Example:
from cognite import CogniteClient
client = CogniteClient(project="my-project", token="my-token")
func = client.functions.create(
name="my-function",
external_id="my-function",
file_id=123456789
)
The zip file must follow the same structure as when you create a function from a folder with the zip file itself as the root folder (there shouldn't be an additional root folder within the zip file).
Additional arguments
-
function_path(string): The relative path from the root folder to the file containing thehandlefunction. Defaults tohandler.py. -
secrets(dict): Secrets that will be stored securely on your function and available call-time. -
env_vars(dict): Environment variables that can be accessed inside your function call-time. -
runtime(string): The function runtime. Valid values are given in the SDK documentation. -
index_url(string): A URL pointing to a different package repository. It supports basic HTTP authentication. -
extra_index_urls(list): A list of URLs pointing to additional python package repositories. Supports basic HTTP authentication.
Be aware of the intrinsic security implications of using the index_url and
extra_index_urls options. These settings can open for attacks known as
dependency
confusion,
whereby the package dependency resolver incorrectly installs a public package with
the same name as the intended private package.
To mitigate this: only use the index_url option and have your private repository server satisfy the following:
- Mirror the public default PyPi package index. Your index should be able to serve public packages from the public index.
- If a package name is shared between a private package in your private index and a public package in the public index, your server must explicitly choose the private package.
Some package index server tools satisfy these requirements out of the box, such as DevPi. In the Python ecosystem, this is made possible when multiple indices are
specified using the This means that if a malicious entity manages to guess the name of a package
hosted in the additional indices, the entity can upload a package with the same name
to the public package index containing malicious code. When resolving, if the
package version isn't pinned, pip will choose the package with the highest
version number. Therefore, if the malicious package has the highest version
number, it will be chosen by pip. The user can, to some degree, mitigate this
risk by pinning the package version. In that case, pip will pull the package
from the private index if that particular version only exists there. However,
if the version exists in both indices, the behavior is undefined, and you
can't determine which index pip will pull the package from. The article 3 Ways to Mitigate Risk When Using Private Package
Feeds
by Microsoft is a good introduction to the dependency confusion problem.Details
Additional information: Dependency confusion
Dependency confusion happens when a software installer is tricked into installing malicious software from a public index instead of the intended private index.--extra-index-url option for pip. When installing a
package, the dependency resolver will look for a package with the requested
name in the default index (PyPI by default, can be overridden by --index-url).
If the requested package isn't found there, it will look at the indices
specified in --extra-index-url.
For a complete list of arguments, see the SDK documentation.
The function definition
The entry point of your function, which must be a synchronous Python function, must be named handle with any of the following arguments:
-
client- a pre-instantiatedCogniteClientautomatically available inside your function call-time. It's instantiated with the same permissions as the entity calling the function (on-behalf-of flow). Note that theclientargument is only specified when you define the function but not when you call it; the client is automatically provided when you call it. -
data- (dict) any data you send to your function.WARNINGSecrets or other confidential information shouldn't be passed via this argument. Use the dedicated
secretsargument in functions.client.create() for this purpose. -
secrets- (dict) serves as a way to send sensitive information to your function that must be available when calling it. You can provide these secrets as a dictionary via the secrets argument inclient.functions.create(). -
function_call_info- (dict) contains information about the function being called. It has the keysfunction_id,call_id, and if the call is scheduled, the keysschedule_idandscheduled_time.
The only requirement for the return of your function is that it's JSON-serializable (and on GCP, is less than 1 MB in size). In general, we recommend that you pass small amounts of data to and from functions and instead read from and write to CDF directly from within your function.
The function client.functions.create() returns a function object with various metadata. One of the properties of this object is status which will start with Queued, change to Deploying when the deploy process has started, and end in Ready if the build was successful, or Failed if it failed. You must wait until the function is Ready before calling it. This typically takes about 3–10 minutes. To retrieve the latest status of your function, do:
func.update()
Call a function
When your function is Ready, you can call it.
Example:
call = func.call(data={"assetNo": 0})
Note that you don’t pass a client here, even though it's part of the function definition. You get it automatically inside the function.
When the function is called, a session is created on behalf of the user, and the client inside the function inherits the user’s permissions and scopes. The client is instantiated with a fresh access token based on the newly created session.
The call object has metadata about the call, but not the response itself:
{
"id": 1234,
"start_time": "2020-07-15 08:23:17",
"end_time": "2020-07-15 08:25:15",
"status": "Completed",
"function_id": 456789
}
To retrieve the response:
call.get_response()
To get the logs:
call.get_logs()
All print statements appear in your logs. If an exception is raised, the trace-back appears in the logs.
Be careful not to print/log or return confidential information from the handle() function, as logs and responses are visible to anyone with functions:read in
the project and aren't treated with the same security measures as secrets.
Functions doesn't currently support the logging module, but print statements will turn up as logs. Sometimes, importing the logging module can hide prints and exception trace-backs in the logs. If you experience Failed calls with no trace-back in the logs, make sure that the logging module isn't imported. If you still don’t see any logs, your function probably ran out of memory during execution. You can check the memory consumption of your function locally with the Memory Profiler.
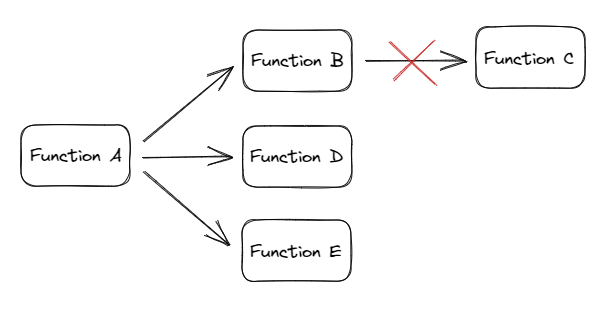
Call a function from a function
You can call a function B from within a function A with the client passed through the handle() function. Just as a session is created for function A on behalf of the user,
a new session will be created for function B from the first sessions (so-called chained sessions). This means that the client in function B also will inherit the
user's permissions and scopes.
Note that you can't further call a function C from within function B in the same way. This is due to a limitation in the sessions API, which only allows for chained sessions one level deep.
Schedule a function
Create a schedule to run a function at regular intervals. Note that when you have created the schedule, you can't change it. You must delete it and create a new schedule.
Example:
schedule = client.functions.schedules.create(
name="my-schedule",
cron_expression="0 0 * * *",
function_id=123456789,
data={"assetNo": 0},
client_credentials={"client_id": "my-client-id", "client_secret": "my-client-secret"}
)
This example runs your function every day at 12:00 AM, as specified by the cron expression. (The time zone for the cron expression is UTC.) You attach the schedule to your function via the function_id argument. Note that you must provide client_credentials. These will be used to create a session for the schedule, which will be kept alive for the lifetime of the schedule.
Deleting a function also deletes the associated schedule.
Upload and run a function in Cognite Data Fusion
In addition to uploading and running functions via the Python SDK and the API, you can upload, run, and share functions directly from CDF at fusion.cognite.com.
Choose CDF when you deploy a single function for experimental or test purposes. In CDF, you can also have an overview on all functions running in a project, and check for failed calls.
Use the SDK when you want to deploy functions that are automatable, scalable, and reusable.
To upload a function to CDF:
-
Navigate to Data management > Build solutions > Functions.
-
Select Upload function, and drag and drop the zip file with at least a Python file called
handler.pywith a function namedhandlewith any of following arguments:data,client,secrets, andfunction_call_info.See Create a function from an uploaded zip file for more information.
-
Give your function a name and, if necessary, fill in the optional fields.
-
Select Upload
Call a function from CDF
To call a function from CDF:
-
Navigate to Data management > Build solutions > Functions.
-
Choose the function you want to call, and then select Call.
-
Optional. To schedule the function:
- Select Create schedule and enter a name, client credentials, and a cron expression for when you want to run your function.
The columns Calls, Schedules, and Details provide more information about the functions. You can also find information about call status, response, and logs.