Data modeling
Build expressive and scalable data models in Cognite Data Fusion (CDF)
About data modeling
Use Cognite's Data Modeling Service (DMS) to build expressive and scalable data models, ingest data to populate the models, and query the models for the data they contain.
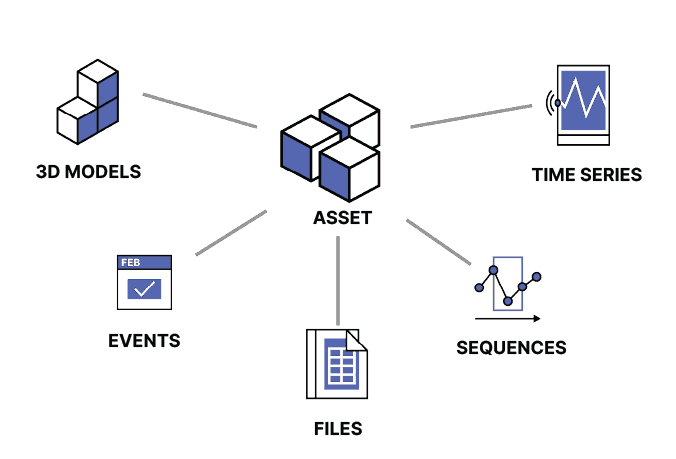
The Cognite Data Fusion (CDF) data modeling features are designed to represent physical structures and processes and help you build a contextualized knowledge graph of your industrial data. Industrial knowledge graphs are implemented as property graphs and lets you model complex systems with a few simple primitives: nodes, edges, and properties.
With a comprehensive industrial knowledge graph as the foundation, you can create solution data models to solve specific use cases. Solution data models offer a perspective of the data specifically tailored to a use case, solution, or application. This model can evolve without breaking existing applications by using new versions of the solution data model.
Refer to these sections for information about data modeling in CDF:
- The concepts section details the core building blocks of CDF data models, for example, spaces, containers, and views.
- The reference section has detailed information about using GraphQL for queries and mutations and about limits and restrictions.
- The examples and best practices section has recommendations for composing and deploying data models and queries.